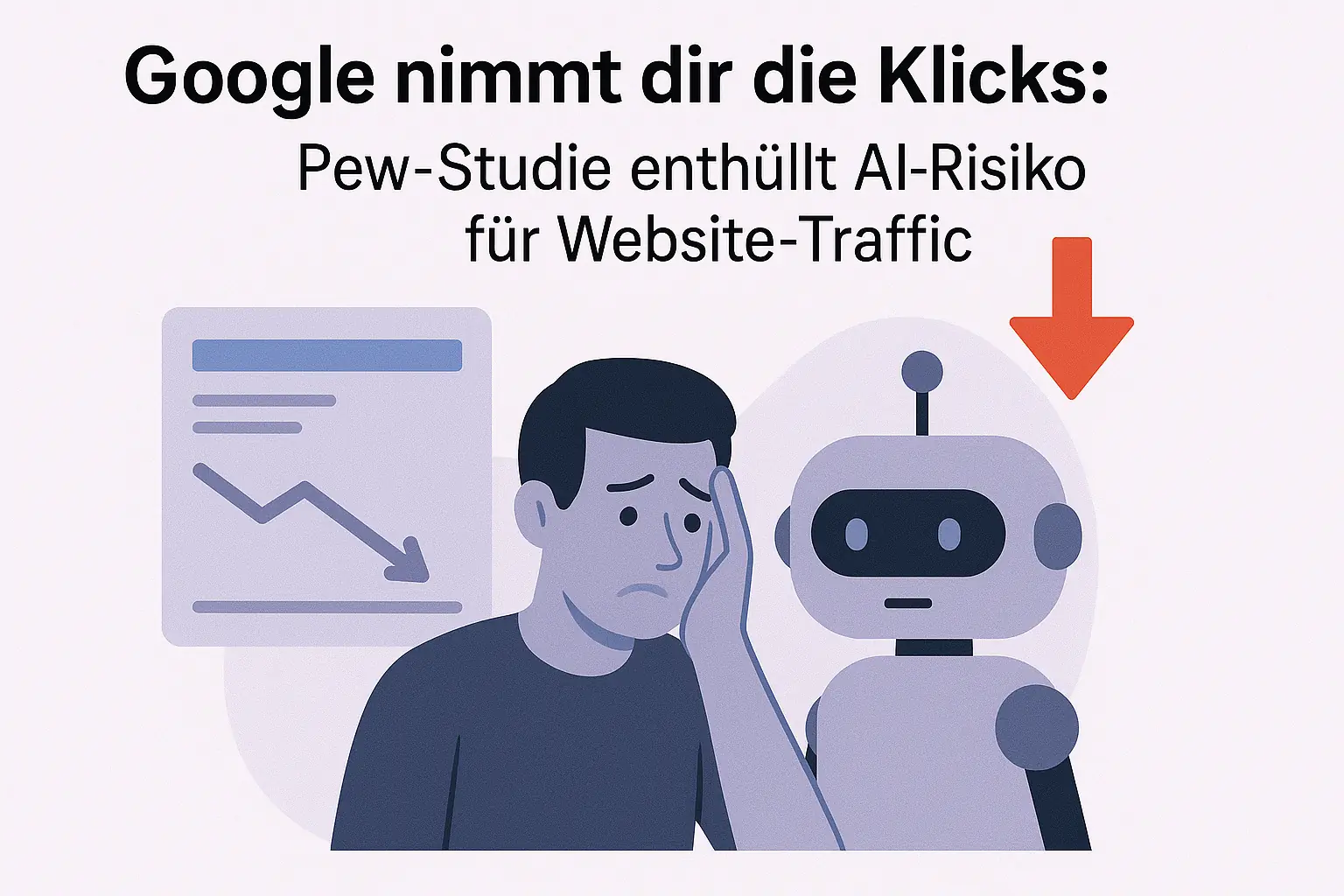
Duplicate content can harm your SEO ranking. Learn 7 essential tips on how to recognize and avoid duplicate content and rank better.
Duplicate Content: Warum er dein Ranking schädigt
Content: Technical SEO · Duplicate Content · Indexierung · Canonicals/Redirects
Warum identische Inhalte deinem Ranking wirklich schaden können
Einleitung: Duplicate Content wirkt harmlos – ist er aber nicht. Suchmaschinen priorisieren eindeutige, relevante, eigenständige Inhalte. Doppelte Texte verwässern Signale, kosten Crawl-Budget und führen dazu, dass Google eine Version bevorzugt – oft nicht deine. Hier erfährst du die 7 wichtigsten Punkte zu Ursachen, Folgen und Lösungen – inklusive Tool-Tipps, Entscheidungslogik und Best Practices.
Warum kritisch: Duplicate Content splittet Rankingsignale, verbraucht Crawl-Budget und zwingt Google zur Kanonisierung.
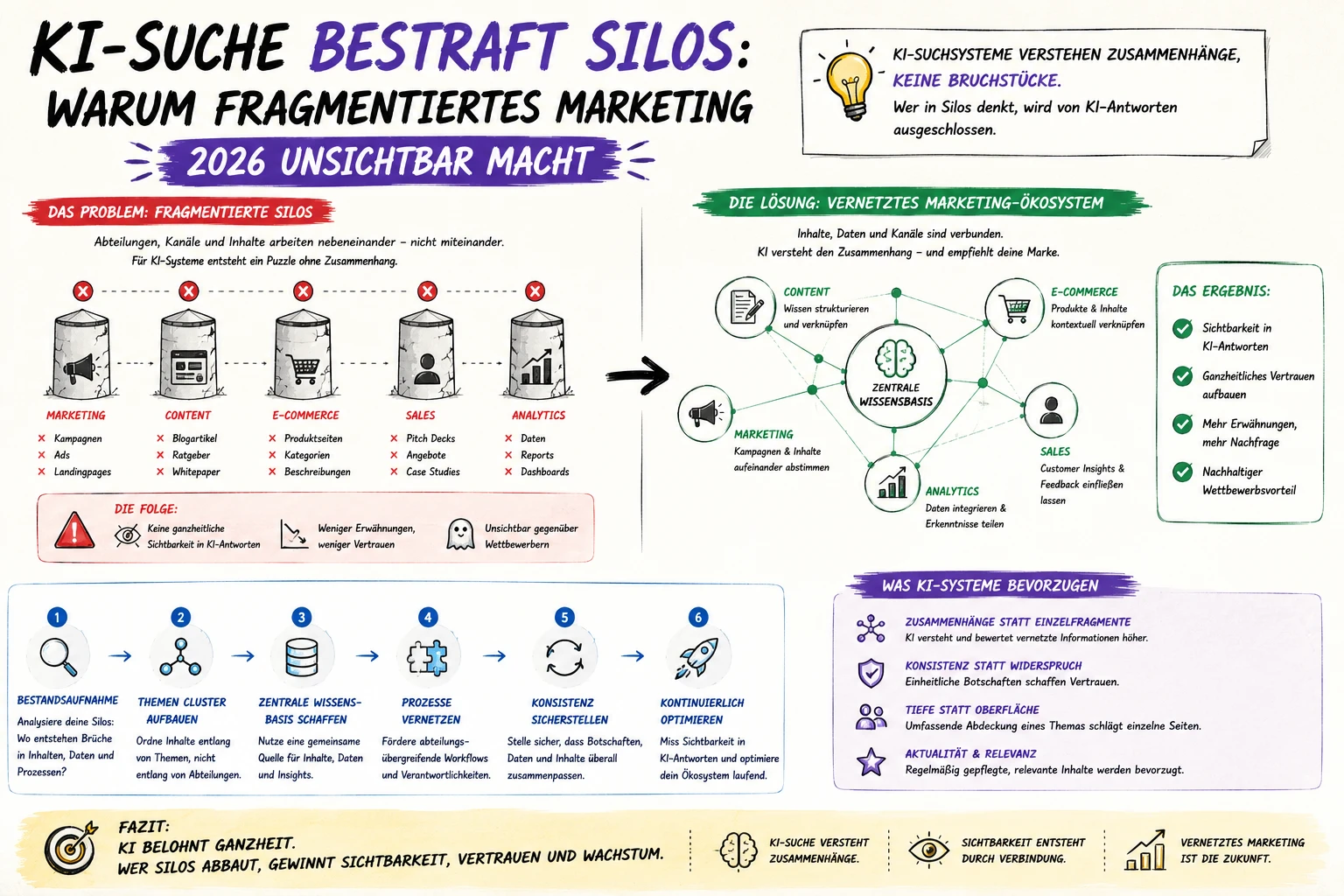
Häufigste Auslöser: Parameter/Tracking, Facetten/Filter, Varianten, Pagination sowie Host-/Protokoll-Duplikate.
Was du steuern musst: Pro Cluster eine Master-URL (301, Canonical oder Noindex – je nach Intent).
Was sofort hilft: Interne Links konsequent auf die Ziel-URL bündeln und „Alternate canonical“-Signale in der GSC überwachen.
Praxisnutzen: Weniger Duplikate = schnellere Indexierung wichtiger Seiten und stabilere Rankings.
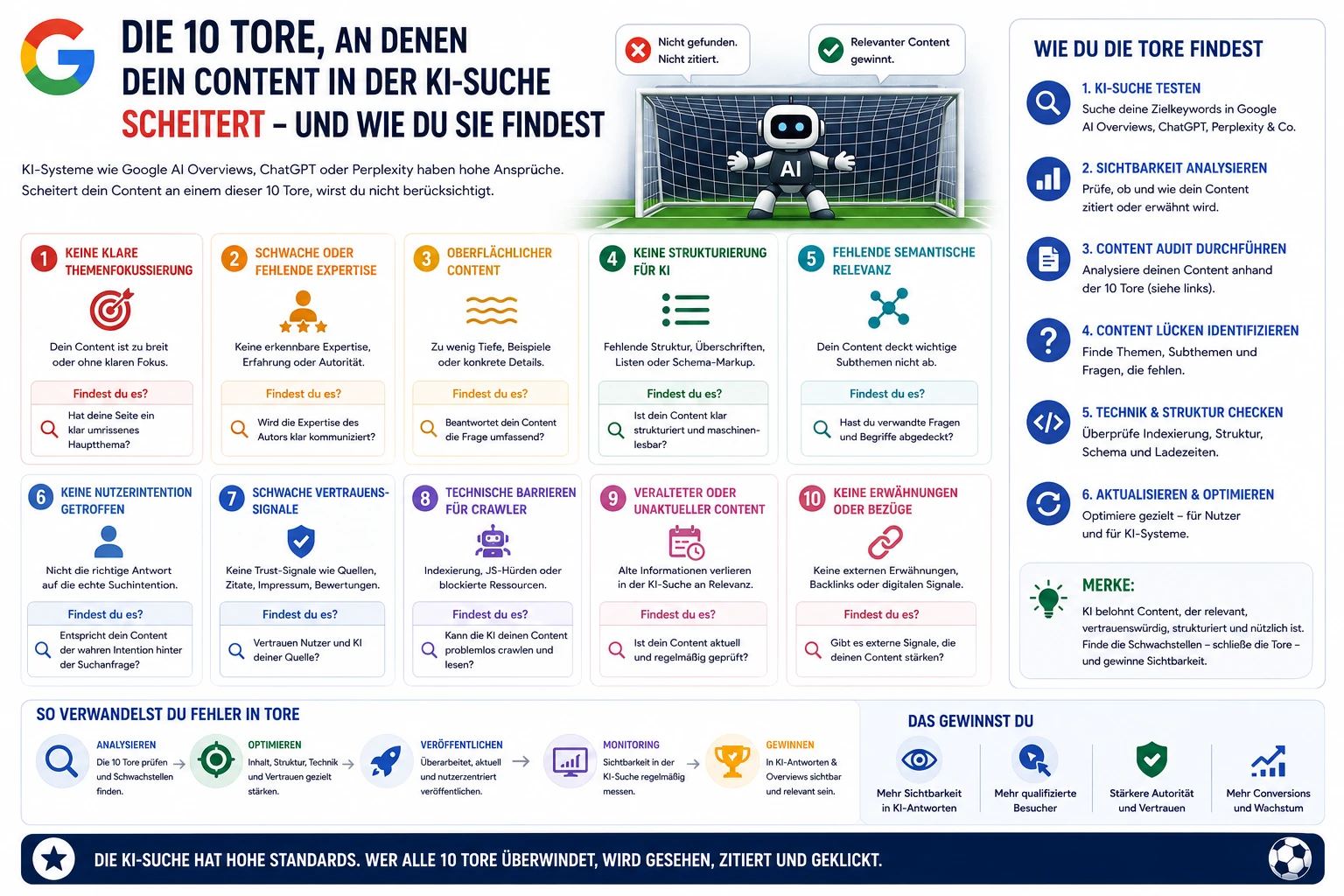
1. Was ist Duplicate Content?
Duplicate Content sind identische oder sehr ähnliche Inhalte auf mehreren Seiten – innerhalb einer Domain (intern) oder domainübergreifend (extern). Er entsteht textuell, strukturell (gleiche H2/H3-Blöcke) oder technisch (Parameter, Hosts, Protokolle).
Intern: gleicher Text unter mehreren URLs (z. B. Druckansicht, Parameter, Facetten, Staging-Livesystem).
Extern: syndizierter Herstellertext, Partnerfeeds, Scraping/Kopien durch Wettbewerber.
Kernproblem: Google muss kanonisieren – nur eine Version gewinnt Sichtbarkeit, die übrigen verlieren. Ohne Steuerung entscheidet Google selbst.
2. Warum ist Duplicate Content für SEO kritisch?
Rankingverluste: konkurrierende Seiten schwächen sich gegenseitig (Signal-Split).
Hinweis: Meist keine Absicht – fehlende technische Leitplanken erzeugen DC „nebenbei“.
Eine oft unterschätzte Quelle sind Session-ID Duplicate Content Probleme: dynamische Parameter und IDs erzeugen Tausende von Duplikaten. Im Ursachenabschnitt zeigen wir, wie man diese Fallen erkennt und beseitigt.
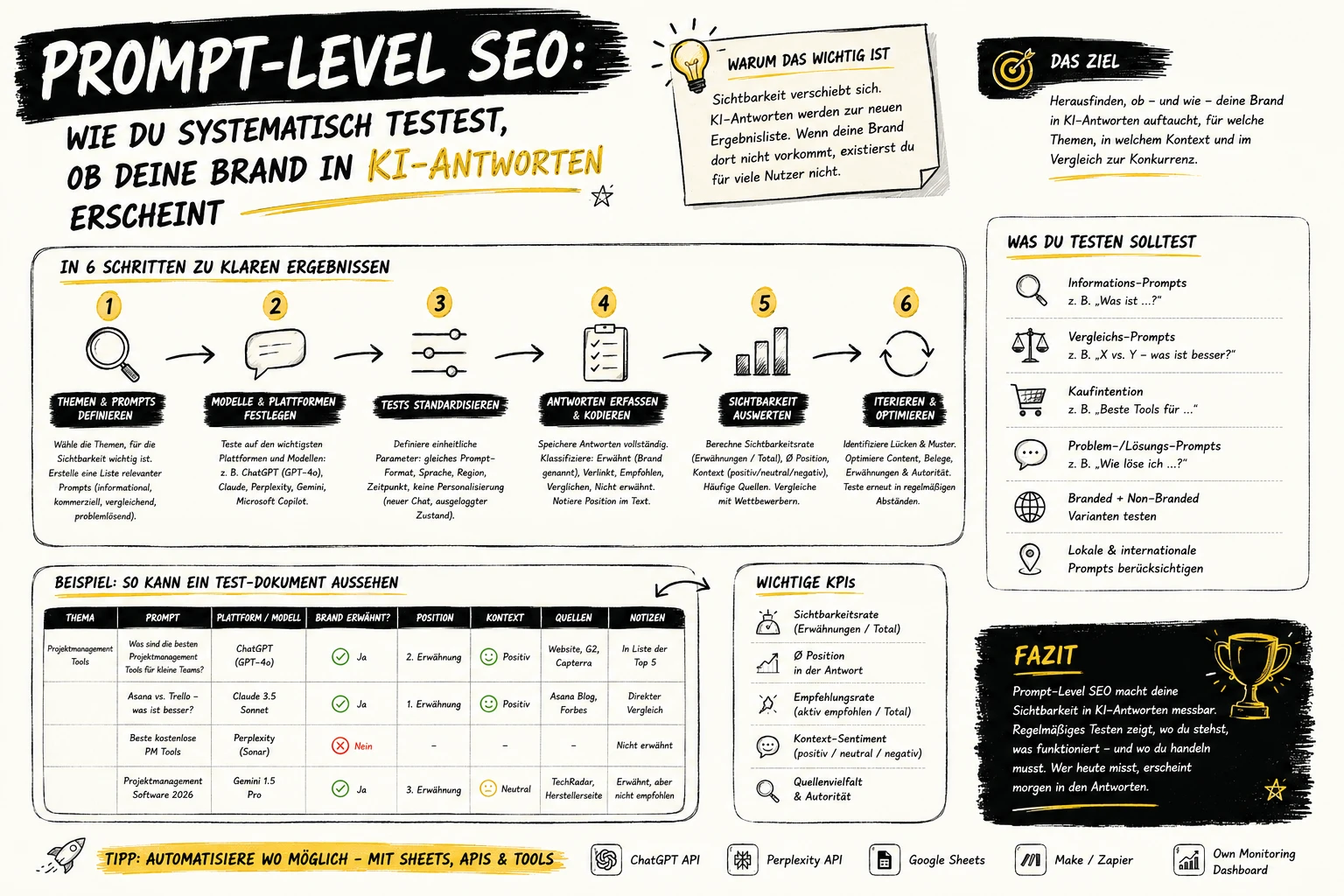
4. Wie erkennt man Duplicate Content?
Setze auf eine Kombination aus Crawler, externem Check und manueller Prüfung. Wichtig ist die Cluster-Sicht (welche URL soll gewinnen?).
Screaming Frog: Hash-Vergleiche, „Exact Duplicates“, Near Duplicates, Titles/Descriptions.
Siteliner: interne Duplikate & Text-Overlap.
Copyscape/Plagscan: externe Kopien finden.
Google Search Console: Index-Bericht, kanonische URL, doppelte Metas, „Seiten mit alternativer kanonischer URL“.
Manuell:"Textausschnitt" + site:domain.de in Google; Cache/quelle ansehen.
Quick-Regex für UTM-Parameter (in Server-Rewrite/NGINX, sinngemäß):
# Beispiel: Tracking-Parameter aus Index entfernen (nur Konzept)
if ($args ~* "(^|&)(utm_[^=]+|gclid|fbclid|ref)=[^&]+") {
# 301 auf kanonische URL ohne Tracking-Parameter
}
Viele Betreiber suchen explizit nach Duplicate Content erkennen Tools. Diese Tools – vom Screaming Frog bis zu Siteliner – sind im Abschnitt „Duplicate Content erkennen“ beschrieben, damit du den Überblick behältst.
Konsolidieren: Themenseiten/Guides statt vieler Thin-Pages mit 300 Wörtern.
Interne Verlinkung: Signale auf die „Master-URL“ bündeln (Breadcrumbs, Related, Cluster-Hub).
Mini-Case (B2C-Shop, 2.8 M URLs)
-42 % reduzierte DC-Cluster nach Canonicals & 301-Rules
+19 % organische Sessions nach 12 Wochen
Maßnahmen: Facetten-Kanonisierung, Host-Konsistenz, Konsolidierung von Varianten, Unique Copy für Topseller. Ergebnis: stabilere Rankings & bessere Crawlbarkeit.
Ein häufiges Keyword ist Canonical Tags richtig setzen, denn falsch gesetzte Canonicals sind eine häufige Fehlerquelle. Wie du diese richtig einsetzt, erfährst du im Entscheidungsbaum (Abschnitt 6).
6. Entscheidungsbaum: 301, Canonical oder Noindex?
Master-Produktseite + Varianten auswählen (Canonical auf Master; Ausnahme: Variante hat eigenen Such-Intent).
Unique Copy für Topseller-Varianten, wenn eigenständige Nachfrage besteht.
Pagination
Klare interne Verlinkung: Seite 1 erläutert Kategorie-Intent & führt tiefer.
Option: „Alle anzeigen“-Seite als Master (Performance beachten), sonst Canonical auf Seite 1 + Paginierungslinks.
Viele SEO-Teams googeln nach Paginierung Duplicate Content vermeiden, um Seiten 1, 2, 3 konsistent zu halten. Unsere Tipps in diesem Abschnitt helfen dir, Filter- und Pagination-Probleme zu lösen.
8. Was sagt Google selbst?
Duplicate Content führt nicht automatisch zu manuellen Strafen. Google filtert Duplikate und zeigt die „relevanteste“ Version. Für dich heißt das: Sichtbarkeit kann ohne Penalty einbrechen, weil deine URL nicht als kanonisch gewertet wird – z. B. wegen externer Links auf eine andere Variante, starker interner Links auf Falschkandidaten oder inkonsistenter Canonicals.
Konsequenz: Kanonisierung aktiv steuern, Inhalte differenzieren, interne Links auf die Ziel-URL ausrichten. Hreflang-Fehler vermeiden (wechselseitige Referenz + Self-Canonical).
Viele Nutzer suchen nach Google Duplicate Content Strafe, doch Google bestraft Duplicate Content nicht direkt – es filtert lediglich die bessere Version. Die Details dazu erklären wir in diesem Abschnitt: Es lohnt sich, genau hinzuschauen, wann ein „Penalty“ nur eine algorithmische Auswahl ist.
Unternehmen stellen sich oft die Frage nach einer Duplicate Content Audit Checklist. Eine Checkliste, um Duplicate Content zu identifizieren, zu konsolidieren und zu überwachen, findest du zusammengefasst im Abschnitt „Best Practices“ und in den vorherigen Kapiteln.
Regelmäßige Audits halten DC klein und Sichtbarkeit hoch.
Author: Sophie (Yellowfrog)
Content-Strategin & SEO-Spezialistin. Fokus: technische Audits, Content-Konsolidierung, E-E-A-T und AI-SERP-Tauglichkeit.
More:
Yellowfrog Blog -
SEO consulting
Quellen (Auswahl):
Google Search Central, Wikipedia: SEO, Yellowfrog-Analysen (2024–2025).
Disclaimer: Dieser Beitrag ersetzt keine Rechts-/Steuerberatung.
Stand: 14.01.2026.
Duplicate Content systematisch reduzieren
Wir konsolidieren DC-Cluster, setzen Canonicals/Redirects sauber auf und stärken deine Hauptseiten – technisch, redaktionell, messbar.




.webp)










.webp)



















































.webp)