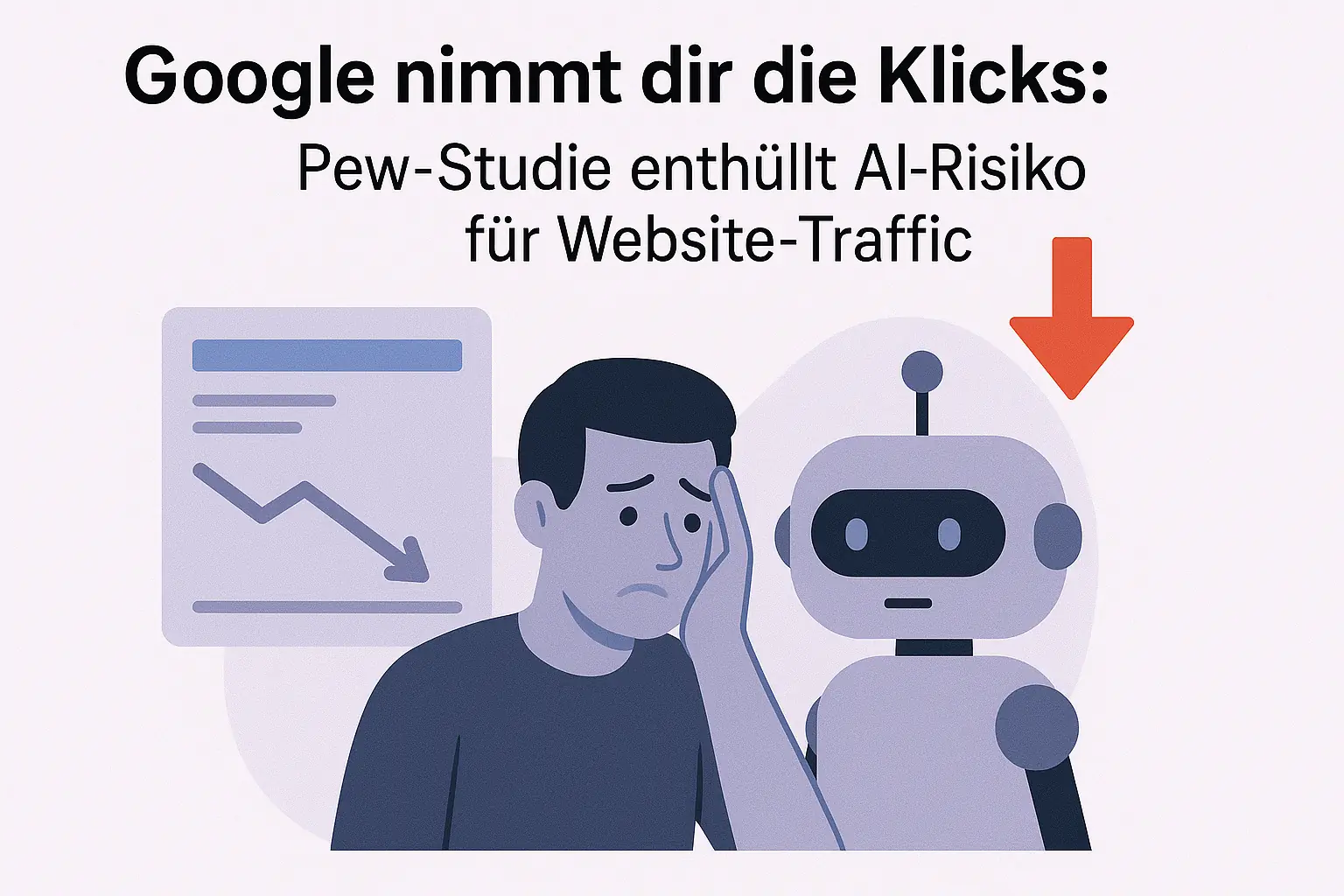
Tracking-Parameter in internen Links können Duplicate Content erzeugen und Linkjuice verwässern. Erfahren Sie, warum sie Ihrer SEO schaden und was hilft.
Tracking-Parameter in internen Links sind eines der häufigsten technischen SEO-Probleme, die sich unbemerkt einschleichen. UTM-Tags für externe Kampagnen sind sinnvoll – aber sobald sie in internen Links landen, richten sie stillen Schaden an: am Crawl-Budget, an der Datenqualität und neuerdings auch an der Zitierfähigkeit in AI-Systemen.
Dieser Beitrag erklärt, warum das Problem unterschätzt wird, was es konkret anrichtet und wie du es sauber löst – ohne auf Tracking-Daten verzichten zu müssen.
Vertiefung: SEO Regeln Grundlagen · GEO & KI-Sichtbarkeit · AI Overviews & SEO
Tracking-Parameter gehören in externe Kampagnen-URLs – nicht in interne Links. Wenn UTM-Tags, fbclid oder benutzerdefinierte Query-Strings in internen Links landen, entstehen parametrisierte Duplikate, die Google crawlen muss, Analytics-Sessions brechen und AI-Crawlern Bandbreite kosten.
Die Lösung heißt DOM-Layer-Tracking: Tracking von der URL-Ebene in die HTML-Ebene verlagern. Interne Links bleiben sauber, Tracking-Daten bleiben vollständig.

?-Zeichen angehängt werden und Metadaten über die Traffic-Quelle eines Klicks enthalten. Typische Beispiele: utm_source, utm_medium, utm_campaign, fbclid, gclid. Sie verändern den Seiteninhalt nicht, erzeugen aber technisch eine eigene URL-Variante.
data-*-Attribute an internen Links können Tag-Manager-Systeme Klick-Events erfassen, ohne die Ziel-URL zu modifizieren. Interne Links bleiben kanonisch und sauber.
UTM-Parameter sind ein nützliches Werkzeug – in externen Kampagnen-Links. Eine E-Mail-Kampagne, ein Social-Ad oder ein Newsletter-Link mit ?utm_source=newsletter&utm_medium=email macht vollkommen Sinn. Du willst wissen, was Traffic bringt.
Das Problem beginnt, wenn diese Parameter in interne Links wandern. Das passiert häufiger als gedacht: Wenn Marketing-Teams Newsletter-Links intern weiterverwenden. Wenn A/B-Test-Tools parametrisierte Varianten verlinken. Wenn CMS-Plugins Tracking automatisch einbauen. Wenn Entwickler externe Link-Konventionen intern kopieren.
Das Ergebnis: Eine Seite, die eigentlich eine kanonische URL hat – /produkt/ – wird intern auch als /produkt/?utm_source=blog&utm_medium=internal verlinkt. Aus Sicht des Crawlers sind das zwei verschiedene URLs.
Merksatz: Was für externe Kampagnen sinnvoll ist, wird intern zum Problem. Tracking-Parameter gehören in den Datenraum – nicht in die URL-Struktur deiner Website.
Wenn eine Website interne Links mit UTM-Parametern verwendet, muss Googlebot alle Varianten crawlen. Bei mehreren Parameterkombinationen entsteht ein Vielfaches der eigentlichen Seitenzahl. Mueller empfiehlt explizit, interne Links auf saubere, kanonische URLs zu setzen.
Jede parametrisierte URL-Variante ist aus Crawler-Perspektive eine potenziell neue Seite. Googlebot crawlt sie – auch wenn rel=canonical auf die saubere URL verweist. Das verbraucht Crawl-Budget, das für neue oder aktualisierte Inhalte fehlt.
Bei größeren Websites mit Tausenden interner Links kann das bedeuten: wichtige neue Seiten werden langsamer entdeckt, aktuelle Inhalte erscheinen verzögert im Index. Die Crawl-Tiefe steigt auf 5–7 Ebenen für Inhalte, die bei sauberer Verlinkung in 2–3 Schritten erreichbar wären.
<link rel="canonical" href="/produkt/"> gesetzt ist: Googlebot crawlt die parametrisierte URL trotzdem. Das Canonical-Tag ist ein Signal, kein Stopp-Befehl.
Das ist die bittere Ironie: Tracking-Parameter in internen Links zerstören genau die Daten, die sie messen sollen.
Szenario: Ein Nutzer kommt via Google organisch auf deine Website. Er liest einen Artikel und klickt einen internen Link mit ?utm_source=blog&utm_medium=internal. Google Analytics wertet die neue Session als eigenständige Quelle blog / internal. Der organische Traffic-Ursprung geht verloren. Die Session wird falsch attributiert. Deine SEO-Berichte zeigen falschen Traffic.
Jede URL mit Parameter ist aus Cache-Perspektive eine eigene Ressource. /produkt/ and /produkt/?utm_source=blog sind zwei Cache-Einträge für identische Inhalte. Das bedeutet: doppelter Speicher, doppelte Verarbeitung, doppelte Auslieferung. Bei CDN-Systemen führt das zu niedrigeren Cache-Hit-Rates und höherer Serverbelastung.
Interne Links übertragen Autorität (Link Equity). Wenn interne Links auf parametrisierte Varianten zeigen, verteilt sich diese Autorität auf mehrere URL-Varianten statt auf die kanonische Seite zu konsolidieren. Das schwächt das Ranking-Potenzial der Zielseiten – ein stiller, schwer messbarer Effekt.
Der häufigste Einwand lautet: „Wir haben rel=canonical auf alle Seiten gesetzt – damit ist das Problem gelöst." Das stimmt nicht.
| Maßnahme | Wirkt bei Indexierung? | Wirkt bei Crawling? | Lösung? |
|---|---|---|---|
rel=canonical | ✓ Ja (Signal) | ✗ Nein | Teilweise |
| GSC URL-Parameter-Tool | ✓ Ja (Signal) | Teilweise | Teilweise |
noindex auf Parametern | ✓ Ja | ✗ Nein (vorerst) | Teilweise |
| DOM-Layer-Tracking | ✓ Ja | ✓ Ja | Vollständig |
Canonical-Tags wirken auf der Indexierungs-Ebene: Sie sagen Google, welche URL bevorzugt im Index erscheinen soll. Sie verhindern aber nicht, dass Googlebot die parametrisierte URL crawlt. Das Crawl-Budget-Problem, das Cache-Problem und das Analytics-Problem bleiben bestehen.
Die einzige vollständige Lösung: Tracking-Parameter aus internen Links entfernen und stattdessen DOM-Layer-Tracking nutzen.
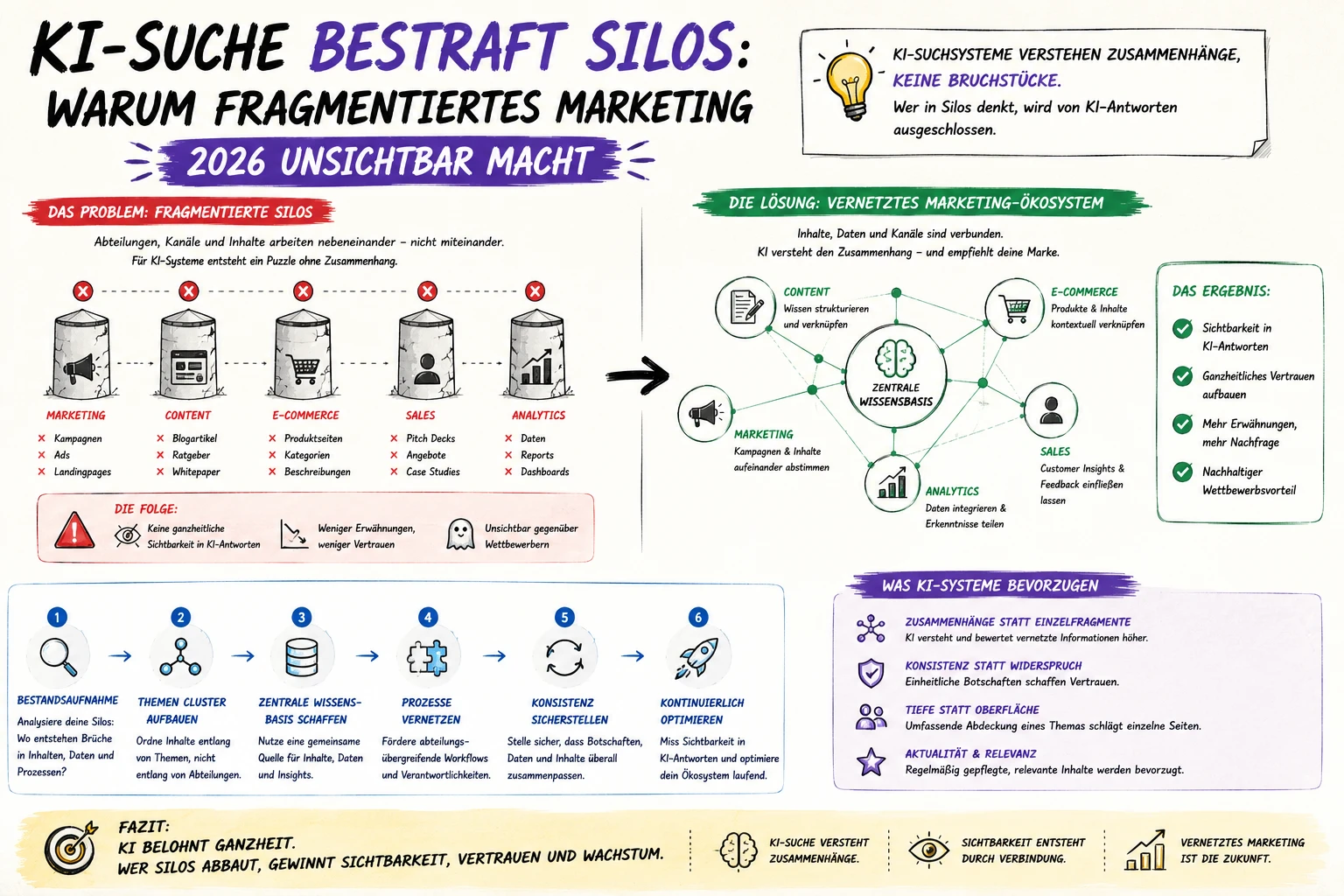
Was bisher ein klassisches technisches SEO-Problem war, bekommt im KI-Zeitalter eine neue Dringlichkeit.
AI-Crawler – die Bots von Perplexity, ChatGPT, Google AI Overviews und anderen LLM-Systemen – fetchen Inhalte in großem Maßstab. Viele haben begrenzte Rendering-Kapazitäten und sind deutlich sensibler für parametrisierte URLs als klassische Suchmaschinen-Crawler.
/produkt/ and /produkt/?utm_source=blog als verschiedene Dokumente behandelt, verschwendet Kapazität auf identische Inhalte – und senkt die Wahrscheinlichkeit, dass dein Inhalt als zitierfähige Quelle ausgewählt wird.
Konkret bedeutet das: Websites mit sauberer URL-Struktur ohne Parameter-Bloat haben eine höhere Zitierfähigkeit in AI-Antworten. Parametrisierte interne Links schaden also nicht nur dem klassischen SEO, sondern auch der GEO-Performance.
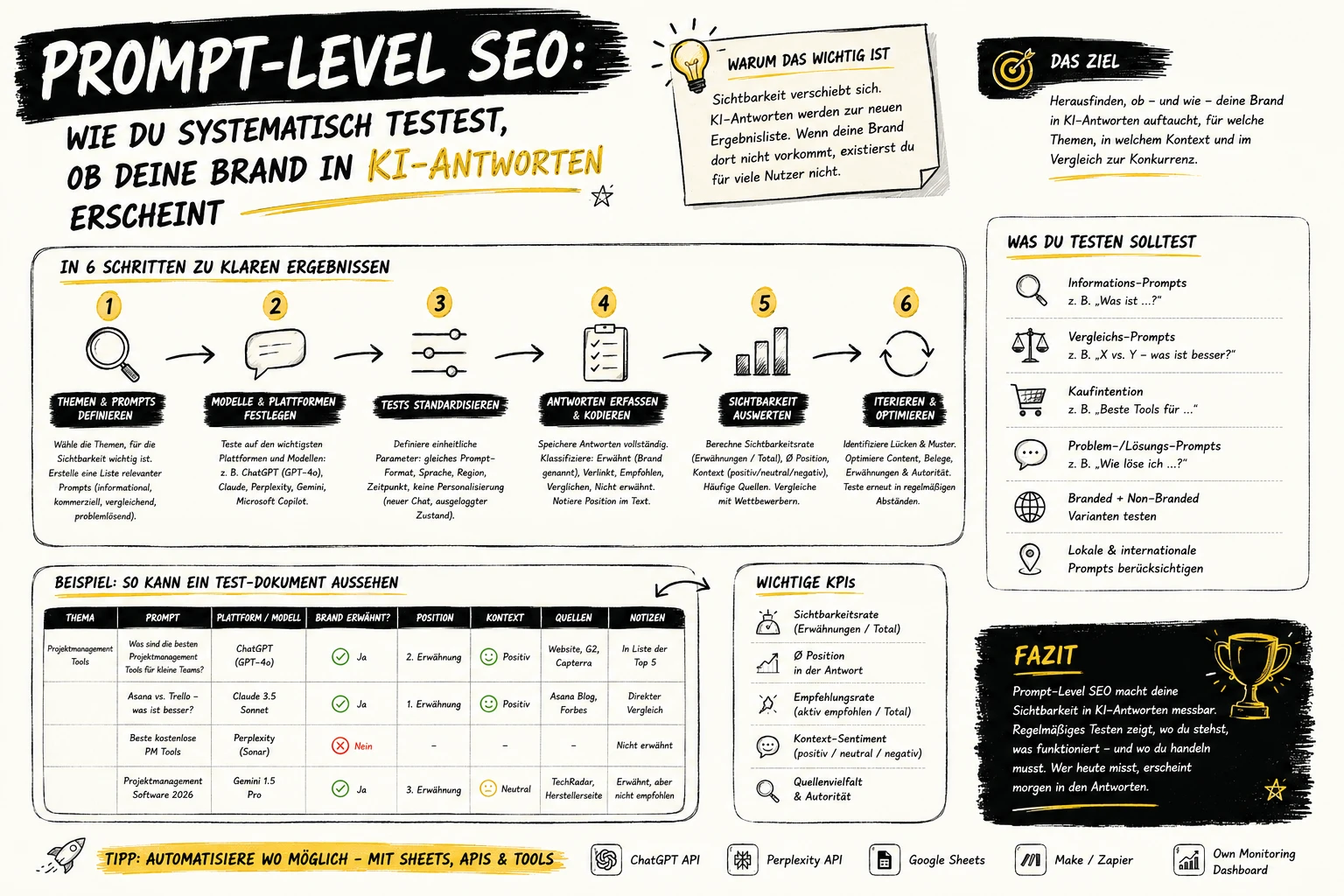
Das Ziel: Tracking-Daten vollständig erhalten, ohne URL-Parameter in internen Links zu verwenden.
Die Lösung heißt DOM-Layer-Tracking. Statt die Tracking-Information in die URL zu schreiben, wird sie als data-*-Attribut direkt am HTML-Link-Element gespeichert. Der Tag Manager erkennt den Klick, liest das Attribut aus und sendet das Analytics-Event – ohne die URL je zu verändern.
<a href="/produkt/?utm_source=blog&utm_medium=internal&utm_campaign=spring"> Zum Produkt </a>
<a href="/produkt/" data-track-source="blog" data-track-medium="internal" data-track-campaign="spring"> Zum Produkt </a>
Trigger: Klick auf alle Links
Bedingung: Klick-Element enthält Attribut "data-track-source"
Tag: GA4 Event "internal_link_click"
Parameter:
link_source = {{Click Element - data-track-source}}
link_medium = {{Click Element - data-track-medium}}
link_campaign = {{Click Element - data-track-campaign}}
Das Ergebnis: Interne Links zeigen auf /produkt/ – sauber, kanonisch, parameterfrei. Google crawlt eine URL. Der Cache hat einen Eintrag. Analytics empfängt vollständige Klickdaten als Event.
? or utm_ enthalten. Ergänze den Search Console Coverage-Report: Welche parametrisierten URLs sind im Index?
data-*-Attribute an internen Links. Konfiguriere Google Tag Manager: Klick-Trigger + Variablen für data-Attribute + GA4-Event-Tag. Teste mit dem GTM-Preview-Modus, bevor du live gehst.
data-track-source, data-track-medium, data-track-campaign am Link. GTM Klick-Trigger → GA4 Event.
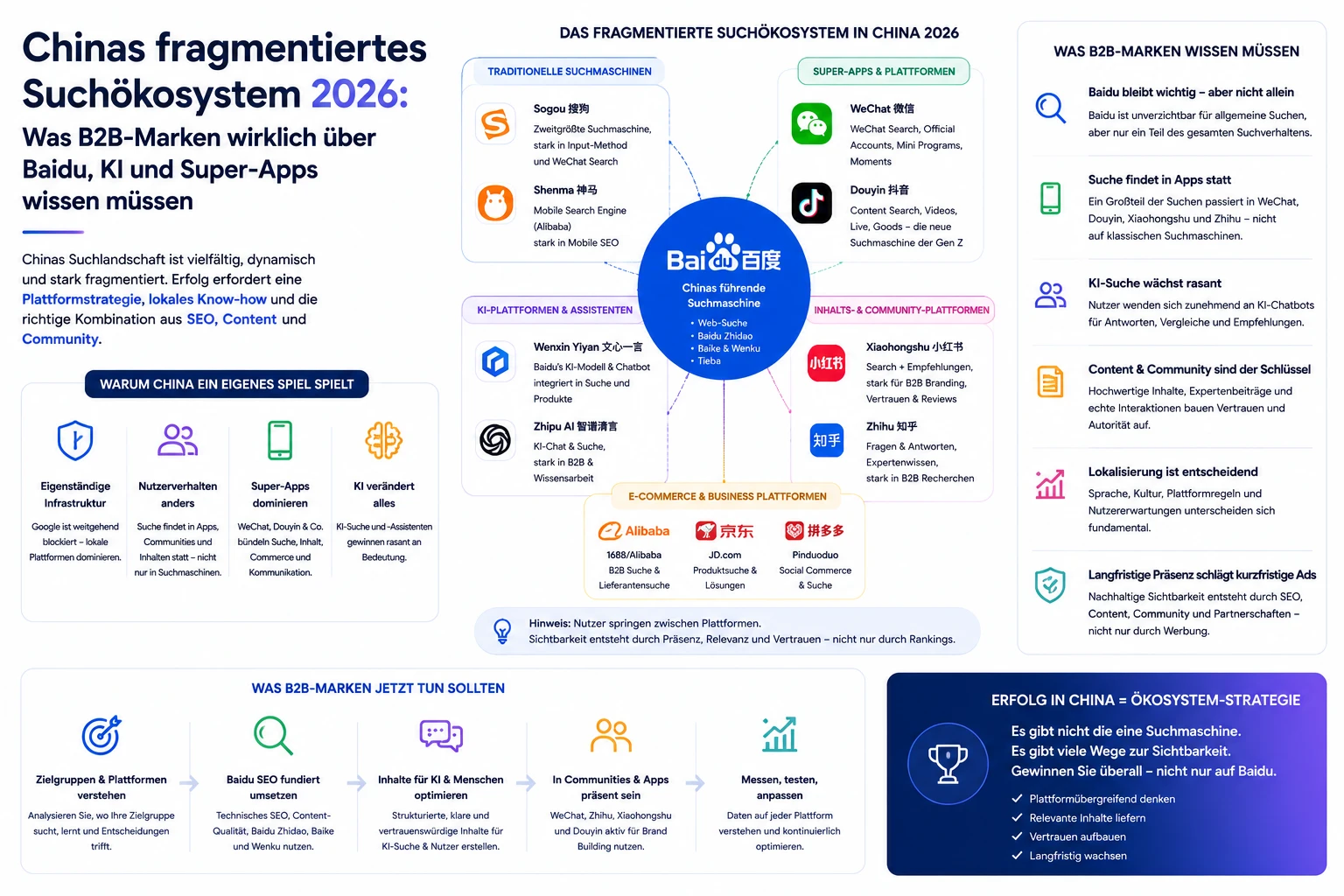
Technische SEO-Probleme haben es schwer im Stakeholder-Meeting. „Crawl-Budget" klingt abstrakt. Hier ist die Übersetzung in Business-Sprache:
| Technisches Problem | Business-Impact | Wer merkt es? |
|---|---|---|
| Crawl-Budget-Verschwendung | Neue Seiten erscheinen verzögert im Google-Index | SEO, Marketing |
| Session-Attributionsfehler | Analytics-Berichte falsch – falsche Entscheidungen | Marketing, Management |
| Cache-Duplikate | Höhere Server-/CDN-Kosten, schlechtere Ladezeiten | IT, Entwicklung |
| Link-Equity-Fragmentierung | Rankings der Zielseiten unter Potenzial | SEO |
| AI-Retrieval-Probleme | Niedrigere Zitierfähigkeit in AI Overviews | SEO, Marketing |
Der stärkste Hebel für die Überzeugungsarbeit ist der Analytics-Punkt. Zeige dem Marketing-Team konkret: Wie viele Sessions werden nach einem UTM-Klick auf internen Link als neue Quelle attributiert? Das ist der Schaden, den sie gerade selbst verursachen.
Und der Win für Marketing: DOM-Layer-Tracking liefert granularere Daten. Statt nur „utm_source=blog" kann ein GTM-Event den genauen Link-Text, die Position im Artikel und den Click-Kontext mitliefern – Daten, die UTM-Parameter nie liefern konnten.
Für weiterführende SEO-Unterstützung: YellowFrog SEO-Beratung · Projekte & Cases
Ja. UTM-Parameter in internen Links erzeugen parametrisierte URLs, die Crawl-Budget verbrauchen, Analytics-Attributionen brechen und Duplicate-Content-Risiken erzeugen. Google John Mueller hat explizit empfohlen, interne Links auf saubere, kanonische URLs zu setzen.
Nein. Canonical-Tags wirken auf Indexierungs-Ebene, nicht auf Crawling-Ebene. Suchmaschinen crawlen parametrisierte URLs weiterhin – das Crawl-Budget-Problem bleibt. Canonical ist notwendig, aber nicht hinreichend.
DOM-Layer-Tracking verlagert Tracking-Informationen von der URL-Ebene in HTML-Attribute. Über data-*-Attribute an internen Links kann Google Tag Manager Klick-Events erfassen, ohne die Ziel-URL zu verändern. Interne Links bleiben kanonisch sauber.
Mit Screaming Frog alle internen Links crawlen und nach ? or utm_ filtern. Google Search Console Coverage-Report zeigt, welche parametrisierten URLs im Index sind. Crawl-Logs liefern das vollständige Bild des Crawler-Verhaltens.
AI-Crawler und LLM-Retrieval-Systeme haben begrenzte Rendering-Kapazitäten. Parametrisierte URLs erzeugen doppelte Cache-Einträge für identische Inhalte – AI-Systeme verschwenden Bandbreite und RAG-Systeme behandeln Duplikate als separate Dokumente, was die Zitierfähigkeit senkt.
Nein. Alle Tracking-Parameter in internen Links sind problematisch: utm_, fbclid, vlid, gclid, msclkid und benutzerdefinierte Query-Strings. Das Prinzip gilt für alle URL-Parameter ohne inhaltliche Relevanz.
Tracking-Parameter in internen Links sind ein typisches Problem, das entsteht, wenn gute Werkzeuge am falschen Ort eingesetzt werden. UTM-Tags sind für externe Kampagnen gemacht – nicht für interne Navigation.
Die gute Nachricht: Die Lösung ist technisch sauber und analytisch besser. DOM-Layer-Tracking liefert präzisere Daten, spart Crawl-Budget und verbessert sowohl klassische SEO-Performance als auch AI-Zitierfähigkeit.
?-Zeichen filtern. Ergebnis = dein konkreter Handlungsbedarf.
Wir prüfen eure interne Verlinkung, Crawl-Budget-Effizienz und AI-Zitierfähigkeit – und zeigen konkret, wo Tracking das Ranking sabotiert.
Kostenlose Erstberatung
.webp)










.webp)



















































.webp)