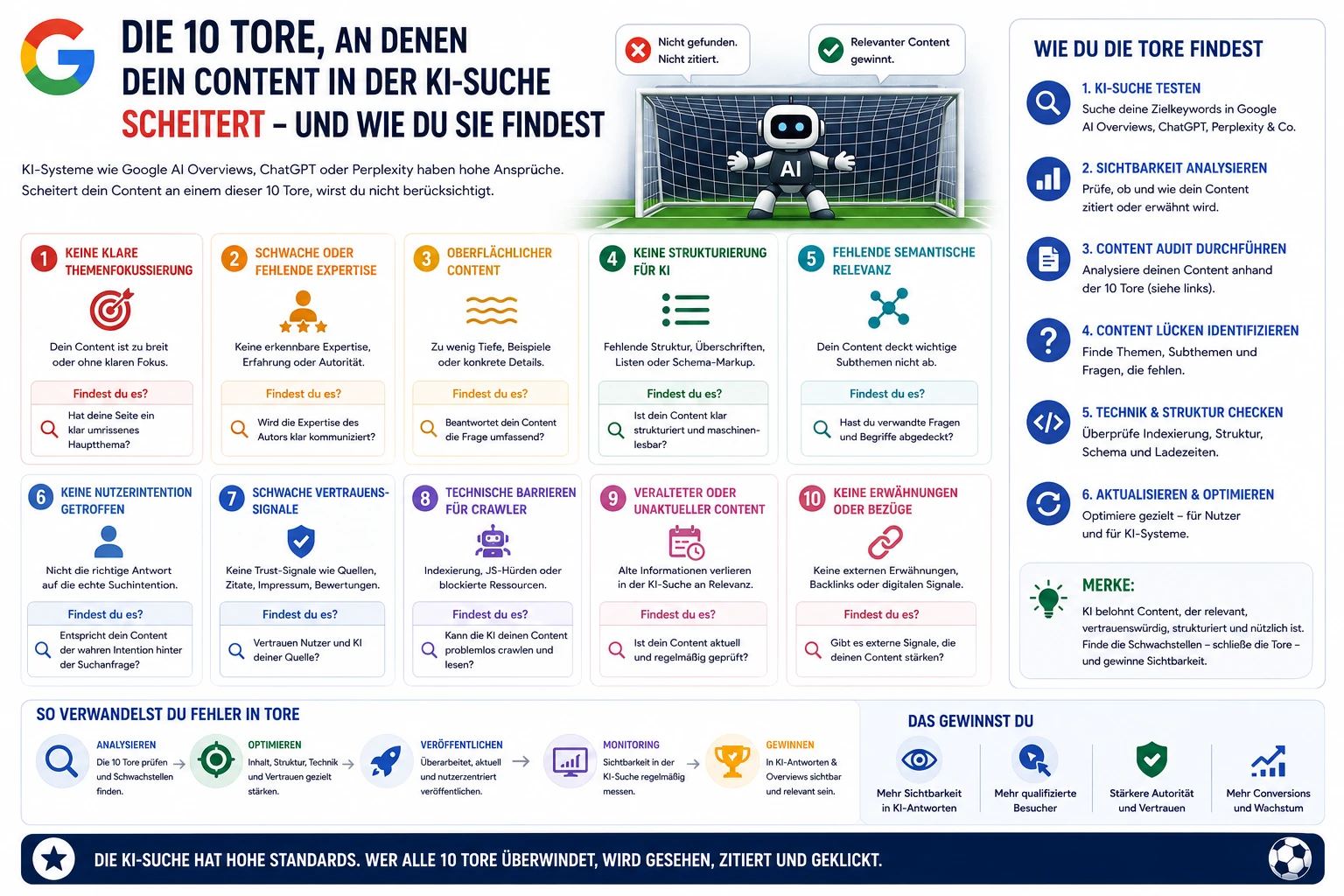
Googles 20–30-Fenster ist eine Hardware-Grenze, kein Algorithmus-Design. Gerichtsaussagen und TurboQuant zeigen: Das SEO-Spielfeld weitet sich. Was jetzt zu tun ist.
Über mehr als ein Jahrzehnt war SEO ein Kampf um die erste Seite. Jedes Tool, jeder Audit, jedes Content-Briefing operierte unter derselben Annahme: Googles Ranking-Systeme bewerten am Ende ein relativ festes Set von 20 bis 30 Kandidaten-Seiten. Diese Annahme war so tief im Fundament der Disziplin verankert, dass sie kaum noch als Annahme erkennbar war — sie galt als Naturkonstante.
Sie ist keine. Gerichtsaussagen aus dem US-vs.-Google-Verfahren, öffentliche Statements von Sundar Pichai und ein neues Google-Research-Paper namens TurboQuant zeigen: Das 20–30er-Fenster existiert nur, weil Google sich derzeit kein größeres leisten kann. Es ist eine Hardware-Grenze, keine algorithmische Notwendigkeit. Und genau diese Grenze beginnt zu fallen. Für SEO bedeutet das: Die Regeln des letzten Jahrzehnts werden nicht überholt — sie werden obsolet.
Vertiefung: Retrieval-First-Strategie aufbauen · Wie KI-Systeme Websites verstehen · Server-Log-Analyse für KI-Crawler
Google bewertet aktuell nur 20 bis 30 Seiten mit seinem teuren Deep-Learning-Ranking-Layer (RankBrain) — nicht aus algorithmischer Notwendigkeit, sondern aus Hardware-Kostengründen. Das hat Pandu Nayak, VP of Search bei Google, 2023 unter Eid im US-Verfahren gegen Google bestätigt. Sundar Pichai bestätigte im April 2026, dass die Memory-Kapazität der zentrale Bottleneck ist. Im März 2026 veröffentlichte Google Research mit TurboQuant eine Technik, die Vektor-Speicher um Faktor 4 bis 4,5 komprimiert und Nearest-Neighbor-Indexing-Kosten auf nahezu null senkt. Wenn diese Technik in die Produktion geht, wächst das bewertbare Kandidaten-Fenster potenziell um ein Vielfaches. Für SEO bedeutet das: Wer heute noch Content gegen Position 1–10 schreibt, optimiert für eine Welt, die in 12–18 Monaten nicht mehr existiert. Die Vorbereitung muss jetzt beginnen — mit drei konkreten Verschiebungen: Retrieval-Messung über Server-Logs, Retrieval-Friendliness statt nur Ranking-Friendliness, und Aufgeben des Top-20–30-Fokus als alleiniger Zielgröße.
Die wichtigste Quelle für das, was wir heute über Googles Ranking-Architektur wissen, ist nicht eine Konferenz-Präsentation oder ein Whitepaper. Es ist ein Gerichtsprotokoll. Am Tag 24 des Verfahrens United States v. Google (Oktober 2023) befragte DOJ-Anwalt Kenneth Dintzer Pandu Nayak, Googles Vice President of Search, unter Eid. Der entscheidende Wortwechsel:
Vier aufeinanderfolgende Bestätigungen. Die Deep-Learning-Komponente, um die SEOs ein Jahrzehnt Theorie gebaut haben, wird absichtlich vom Großteil des Index ferngehalten — weil Google es sich nicht leisten kann, sie breiter anzuwenden.
Die Architektur dahinter ist noch aufschlussreicher. Auf Seite 6406 desselben Protokolls beschrieb Nayak Richter Mehta die klassische Postings-List-Retrieval-Mechanik:
Der Kern des Retrieval-Mechanismus schaut auf die Wörter der Anfrage, läuft die Liste runter — sie heißt Postings-List. Man kann die Listen nicht bis zum Ende durchlaufen, weil sie zu lang wären.
Der Korpus wird auf „Zehntausende" von Seiten reduziert, bevor das Ranking überhaupt beginnt. Aus diesem Pool erreichen nur die obersten 20 bis 30 Ergebnisse den Deep-Learning-Layer. Das widerspricht direkt der Art, wie die meisten SEO-Kommentare Google beschreiben. Die Branche behandelt RankBrain, BERT und andere Deep-Learning-Komponenten als die Definition, wie Google rankt. Unter Eid beschrieb Nayak sie als kostspielige optionale Layer, angewendet auf ein schmales Fenster, das klassische Retrieval bereits gefiltert hat.
Am 7. April 2026 sprach Sundar Pichai im Cheeky Pint-Podcast mit John Collison und Elad Gil über die aktuelle Lage. Die zentrale Aussage:
Pichai nannte fünf konkrete Engpässe, die kurzfristig nicht durch CapEx-Erhöhungen gelöst werden können:
| Bottleneck | Was es bedeutet |
|---|---|
| Wafer-Starts | Kapazitäten in den Halbleiter-Foundries — limitiert durch TSMC & Co. |
| Memory | Speicher-Chips — laut Pichai der hartester Engpass |
| Power & Energie | Stromversorgung für Data Center, oft regulatorisch limitiert |
| Data-Center-Permits | Bauanträge und Genehmigungen — politisch verzögert |
| Fachkräfte | Spezialisten für Aufbau und Betrieb der Infrastruktur |
Pichai betonte vor allem Memory:
Es gibt keinen Weg, wie die führenden Memory-Unternehmen ihre Kapazität dramatisch verbessern werden.
Für den Horizont 2026 bis 2027 kann Google sich am Memory-Bottleneck nicht vorbeikaufen. Höhere Preise schaffen keine zusätzliche Kapazität.
Zwei Wochen vor Pichais Cheeky-Pint-Auftritt veröffentlichte Google Research einen Blog-Post zu einer neuen Technik: TurboQuant. Das zugehörige arXiv-Paper „TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate" wurde von Forschern bei Google Research, Google DeepMind und der NYU verfasst.
Die Kernergebnisse:
Das Paper deckt zwei Anwendungen ab: KV-Cache-Kompression in Gemini, und Nearest-Neighbor-Search in Vector-Databases. Die meiste Berichterstattung fokussierte auf die Gemini-Anwendung. Die zweite — die Vektor-Datenbank-Anwendung — ist für die Such-Architektur die kritische.
Die Frage hat sich verschoben — nicht mehr „kann die Kostengrenze verschoben werden?", sondern „was tun SEOs, bevor sie verschoben wird?"
Warten, bis SERPs bestätigen, dass sich das Retrieval geweitet hat, bevor man strategisch reagiert, ist die verlierende Strategie. Die kompetitive Spielfläche verschiebt sich. Wenn das in Rank-Tracking-Tools sichtbar wird, ist die Positionierungs-Arbeit für den nächsten Zyklus bereits abgeschlossen — von anderen.
Die Verschiebung ist nicht nur technisch — sie ist konzeptionell. Ranking-Optimierung fragt: „Wie komme ich höher in einer bekannten Liste?" Retrieval-Optimierung fragt: „Bin ich überhaupt in der Liste, aus der gerankt wird?" Das sind unterschiedliche Probleme mit unterschiedlichen Lösungen.
Rank-Tracking-Tools messen Positionen innerhalb des Sets. Sie sagen nichts darüber, ob eine Seite überhaupt für das Set qualifiziert war. In klassischer Suche war das weniger relevant, weil das Set schmal war. In KI-vermittelter Retrieval — und in einem geweiteten RankBrain-Fenster, wenn es kommt — ist diese Unterscheidung das gesamte Spiel.
Ranking-Signale, die du bereits kennst: Topical Authority, Link-Equity, Query-Intent-Match. Retrieval-Systeme suchen etwas anderes:
Eine Seite, die für Ranking geschrieben ist, vergräbt ihre Hauptaussage oft unter Kontext und Vorreden. Eine retrieval-fähige Seite stellt den Claim an den Anfang.
Das Fenster ist eine Hardware-Beschränkung, die jahrelang hielt, weil sich niemand bei Google leisten konnte, sie zu weiten. Content gegen „was rankt in Positionen 1–10 für diese Query" zu briefen, heißt gegen einen Snapshot eines Fensters zu briefen, das schmaler ist, als es nötig wäre — aus reiner Hardware-Ökonomie.
Wenn sich die Ökonomie ändert, weitet sich das Fenster. Content, der gebaut wurde, um in einem schmalen Set zu konkurrieren, wird einer breiteren Konkurrenz gegenüberstehen, sobald sich das Set ausdehnt. Die Marge geht an Content, der stark genug war, von Beginn an in ein breiteres Kandidaten-Set einzutreten.
Der schnellste konkrete Test, ob deine Seiten retrieval-eligible sind: Server-Log-Analyse. Zwei Klassen von Retrieval-User-Agents sind relevant.
Diese bauen den Korpus auf, aus dem KI-Systeme ziehen:
Diese ziehen Seiten on-demand, wenn jemand ein AI-Modell zu einem Thema fragt, das deine Seite abdeckt:
Die SEO-Branche steht vor einer der größten konzeptionellen Verschiebungen seit der Einführung von RankBrain selbst. Unsere Einschätzung — basierend auf den Mustern, die wir bei Beratungs-Kunden seit Anfang 2025 sehen:
Drei Beobachtungen stützen das:
Google bewertet nur die obersten 20 bis 30 Kandidaten-Seiten pro Query mit seinem teuren Deep-Learning-Ranking-Layer (RankBrain). Davor läuft klassisches Postings-List-Retrieval, das den Korpus auf „Zehntausende" reduziert. Aus diesem Pool erreichen nur 20–30 Seiten den finalen Ranking-Layer. Bestätigt durch Pandu Nayak unter Eid im US-Gerichtsverfahren 2023.
Nicht aus algorithmischen Gründen, sondern aus Hardware-Kosten. Deep-Learning-Ranking ist memory-intensiv. Größere Kandidaten-Sets würden mehr Memory benötigen, als Google sich aktuell leisten kann. Pichai bestätigte April 2026, dass Memory einer der härtesten Supply-Bottlenecks ist und durch CapEx kurzfristig nicht lösbar.
TurboQuant ist ein Algorithmus von Google Research, Google DeepMind und der NYU, der Vektor-Repräsentationen um Faktor 4 bis 4,5 komprimiert — bei vergleichbarer Performance. Indexierungs-Zeit für Nearest-Neighbor-Search wird auf nahezu null reduziert. Wenn deployed, könnte er die Memory-Ökonomie hinter dem 20–30-Fenster grundlegend verändern.
Nein, nicht bestätigt. Google hat den Algorithmus im März 2026 publiziert. Berichte beschreiben ihn als Lab-Breakthrough. Das März-2026-Core-Update enthielt keine öffentlichen Hinweise zu Retrieval-Effizienz oder Vektor-Quantisierung. Google nutzt seit Jahren quantisierte Vektor-Suche über ScaNN — TurboQuant erweitert diesen Ansatz.
Ranking-Friendliness optimiert für Topical Authority, Link-Equity und Query-Intent-Match. Retrieval-Friendliness optimiert dafür, dass eine Seite überhaupt im Kandidaten-Set erscheint: klare, in sich geschlossene Aussagen in den ersten 100 Wörtern, Entity-Verknüpfungen, zitierfähige Statistiken, umgebende Evidenz. Beide sind wichtig — werden aber unterschiedlich optimiert.
Über Server-Log-Analyse. Zwei Crawler-Klassen tracken: Such-Index-Crawler (OAI-SearchBot, Claude-SearchBot, PerplexityBot, Applebot) und User-driven Agents (ChatGPT-User, Claude-User, Perplexity-User). Letztere führen kein JavaScript aus und sind in GA4 unsichtbar. Wenn deine wichtigen Seiten in keiner der Listen erscheinen, sind sie nicht retrieval-eligible.
Nicht aufhören — aber nicht mehr ausschließlich. Top-10 bleibt wichtig, solange das schmale Fenster existiert. Aber Briefings sollten nicht mehr „nur was rankt in Positionen 1–10" als Wettbewerbsanalyse nehmen. Sobald das Fenster weiter wird, konkurriert Content mit einem deutlich größeren Set. Wer dann erst anfängt, breit zu denken, hat den Wechsel verpasst.
Es gibt keine offizielle Timeline. TurboQuant ist publiziert, aber nicht in Production confirmed. Realistisch: 12–18 Monate, falls die Memory-Constraints sich nicht verschärfen und der Algorithmus die Produktions-Reife erreicht. Wichtig: Die Vorbereitung hängt nicht von der genauen Timeline ab — Retrieval-Friendly Content gewinnt heute schon in KI-Suche, unabhängig vom Google-Deployment.
Server-Logs der letzten 30 Tage ziehen, Retrieval-User-Agents zählen. Wenn die Zahl niedrig ist: Content-Audit auf Retrieval-Friendliness (klare Claims in ersten 100 Wörtern, Entity-Verknüpfungen, zitierfähige Datenpunkte). Das ist machbar in einem Sprint — und liefert sofort messbare KI-Sichtbarkeits-Effekte, unabhängig von Googles Timeline.
Die SEO-Branche operiert seit Jahren in einem Spielfeld, dessen Größe sie für gegeben hielt. Die Gerichtsaussagen aus dem US-vs.-Google-Verfahren und die Veröffentlichung von TurboQuant zeigen: Diese Größe war eine Hardware-Entscheidung, keine algorithmische. Und sie ist nicht stabil.

Wir analysieren deine Server-Logs auf KI-Crawler-Aktivität, auditieren deine Retrieval-Friendliness und positionieren deine Inhalte für das geweitete Kandidaten-Fenster — bevor der Wettbewerb es tut.
Kostenlose Erstberatung
.webp)










.webp)



















































.webp)