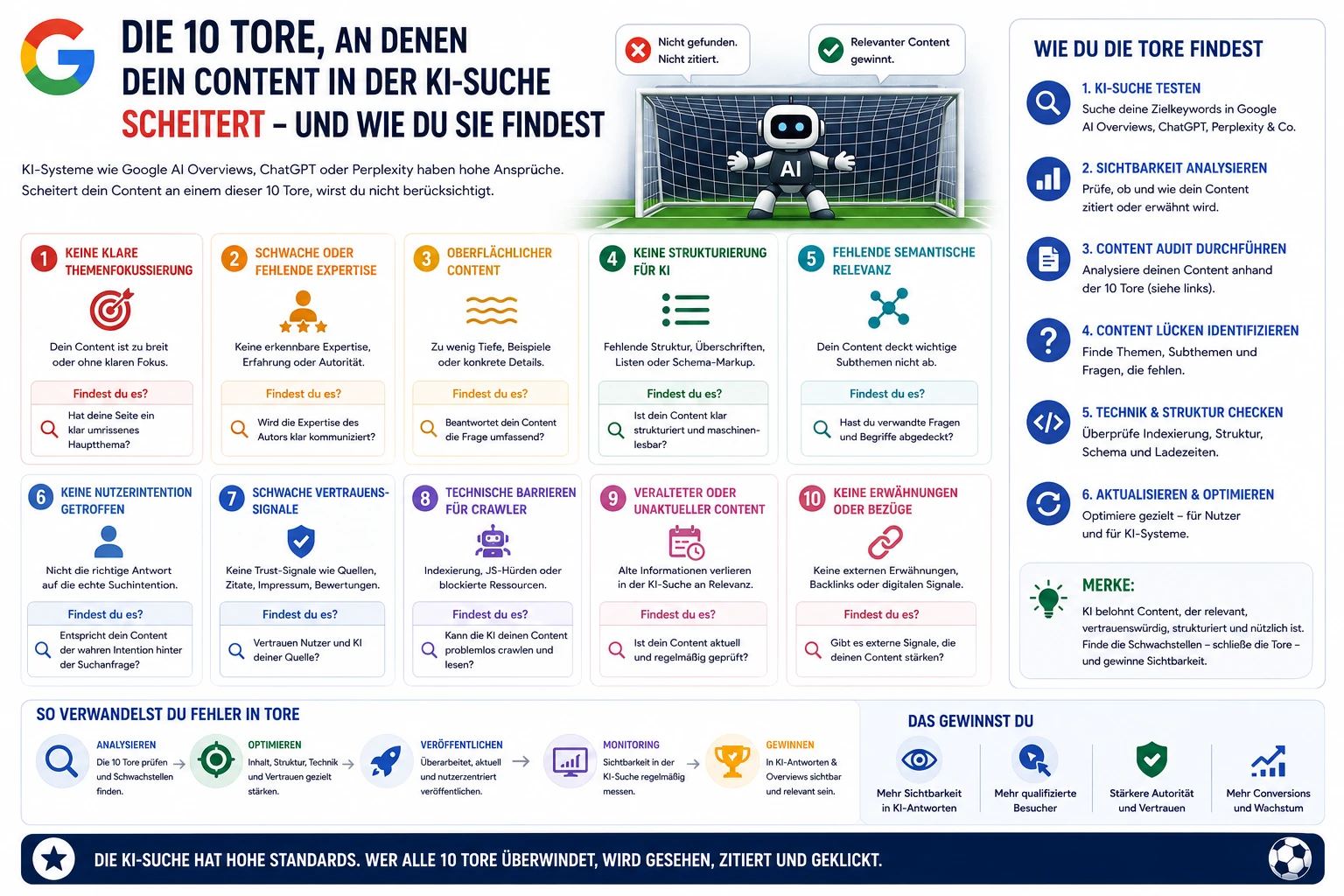
Kryptografische Bot-Identität: Was Googles Web Bot Auth für SEO und KI-Agenten bedeutet
Sophie
May 16, 2026
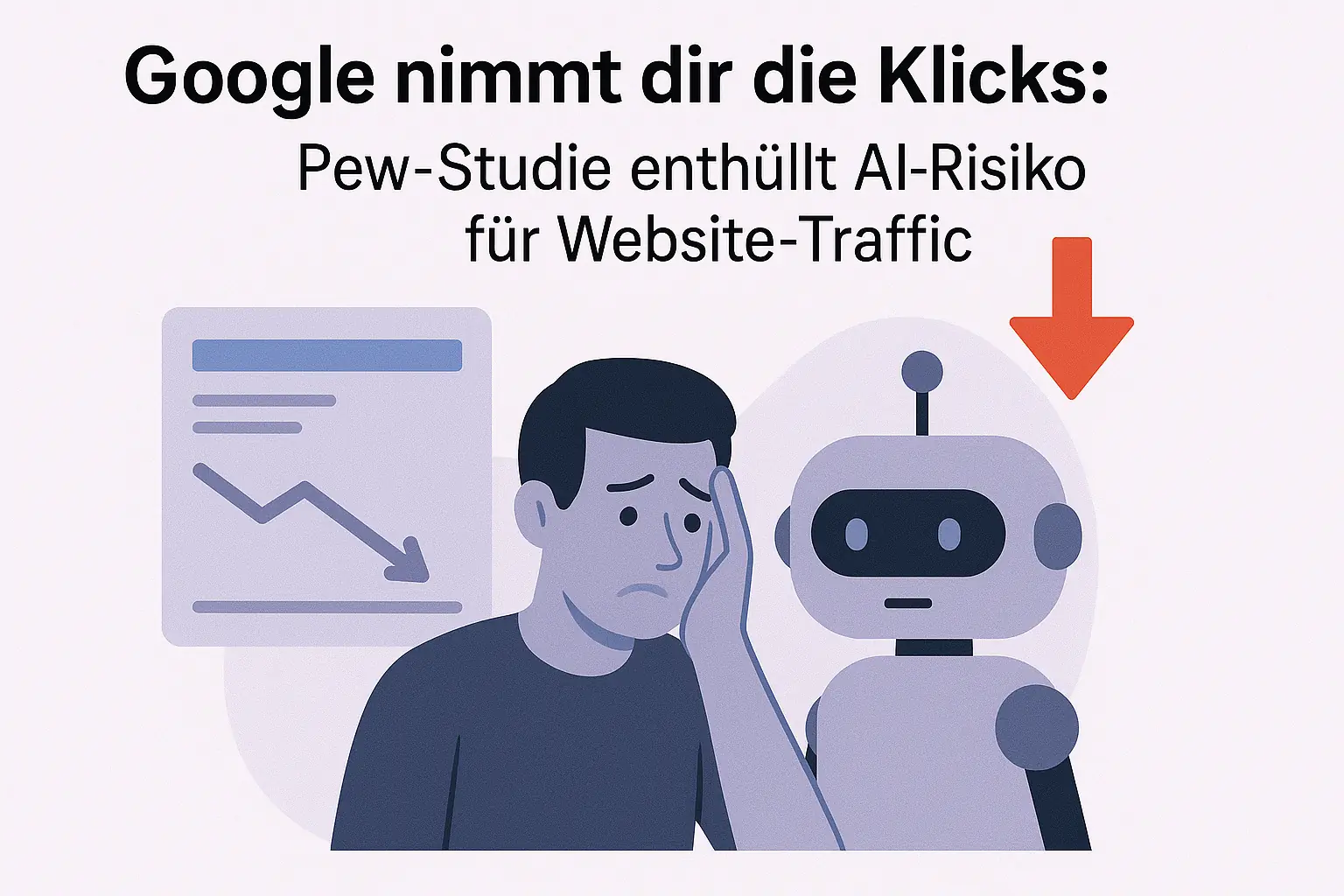
Web Bot Auth ist Googles experimentelles Protokoll für verifizierte Bot-Identität. Was das für SEO, AI-Crawler und Publisher bedeutet – und was jetzt zu tun ist.
Kategorie: Technisches SEO & Bot-ManagementLesezeit: 8 Min.Fokus: Web Bot Auth, KI-Agenten, Crawler-Authentifizierung
Kryptografische Bot-Identität: Was Googles experimentelles Web Bot Auth für SEO und KI-Agenten bedeutet
User-Agent-Strings sind trivial zu fälschen. IP-Adressen wechseln. Reverse-DNS-Lookups sind unzuverlässig. Das sind keine neuen Erkenntnisse — aber in einer Welt, in der KI-Agenten zunehmend das Web crawlen, kaufen und handeln, wird das alte Identitätsproblem plötzlich existenziell.
Google hat im Mai 2026 die Dokumentation für Web Bot Auth veröffentlicht — ein experimentelles kryptografisches Protokoll, das Bot-Anfragen durch digitale Signaturen verifizierbar macht. Es ist noch kein Standard, noch kein breiter Rollout. Aber es zeigt die Richtung, in die die Bot-Authentifizierung geht.
der Web-Anfragen stammt 2026 von automatisierten Quellen – Bots, Crawler und KI-Agenten
Branchenbeobachtung 2026
Trivial
fälschbar: User-Agent-Strings, IP-Adressen, Reverse-DNS – alle bisherigen Bot-Identifikationsmethoden
Google Developers, Mai 2026
Exp.
Status von Web Bot Auth: Google testet nur mit ausgewählten KI-Agenten auf eigener Infrastruktur
Google Developers, Mai 2026
IETF
Working Group entwickelt das zugrundeliegende HTTP Message Signatures Standard – offen und interoperabel
IETF / Google, 2026
Executive Summary
Web Bot Auth ist Googles Antwort auf das wachsende Problem der Bot-Impersonation: KI-Agenten, Scraper und andere automatisierte Systeme können sich heute als legitime Crawler ausgeben ohne nennenswerte technische Hürden. Das neue Protokoll erlaubt es Bots, ihre Anfragen kryptografisch zu signieren — ähnlich wie HTTPS Webseiten-Identitäten sichert. Noch ist Web Bot Auth experimentell und nicht universell ausgerollt. Aber für SEOs, Publisher und Entwickler lohnt sich das Verständnis jetzt.
Rund ein Drittel aller Web-Anfragen stammt heute von automatisierten Quellen. Ein erheblicher Teil davon ist legitim: Googlebot, ClaudeBot, GPTBot, PerplexityBot — Crawler, die Inhalte für Suche und KI-Antworten indexieren. Ein anderer Teil sind Impersonatoren: Scraper und Bots, die sich als legitime Crawler ausgeben, um Sperrmechanismen zu umgehen.
Das bekannte Muster aus technischen Analysen: Ein erheblicher Teil des vermeintlichen ClaudeBot-Traffics auf einzelnen Sites stammt nicht aus Anthropics offiziellen IP-Ranges, sondern aus anderen Cloud-Infrastrukturen. Fast sicher Scraper, die sich als ClaudeBot ausgeben. Weder IP-Adresse noch User-Agent-String konnten das zuverlässig aufdecken.
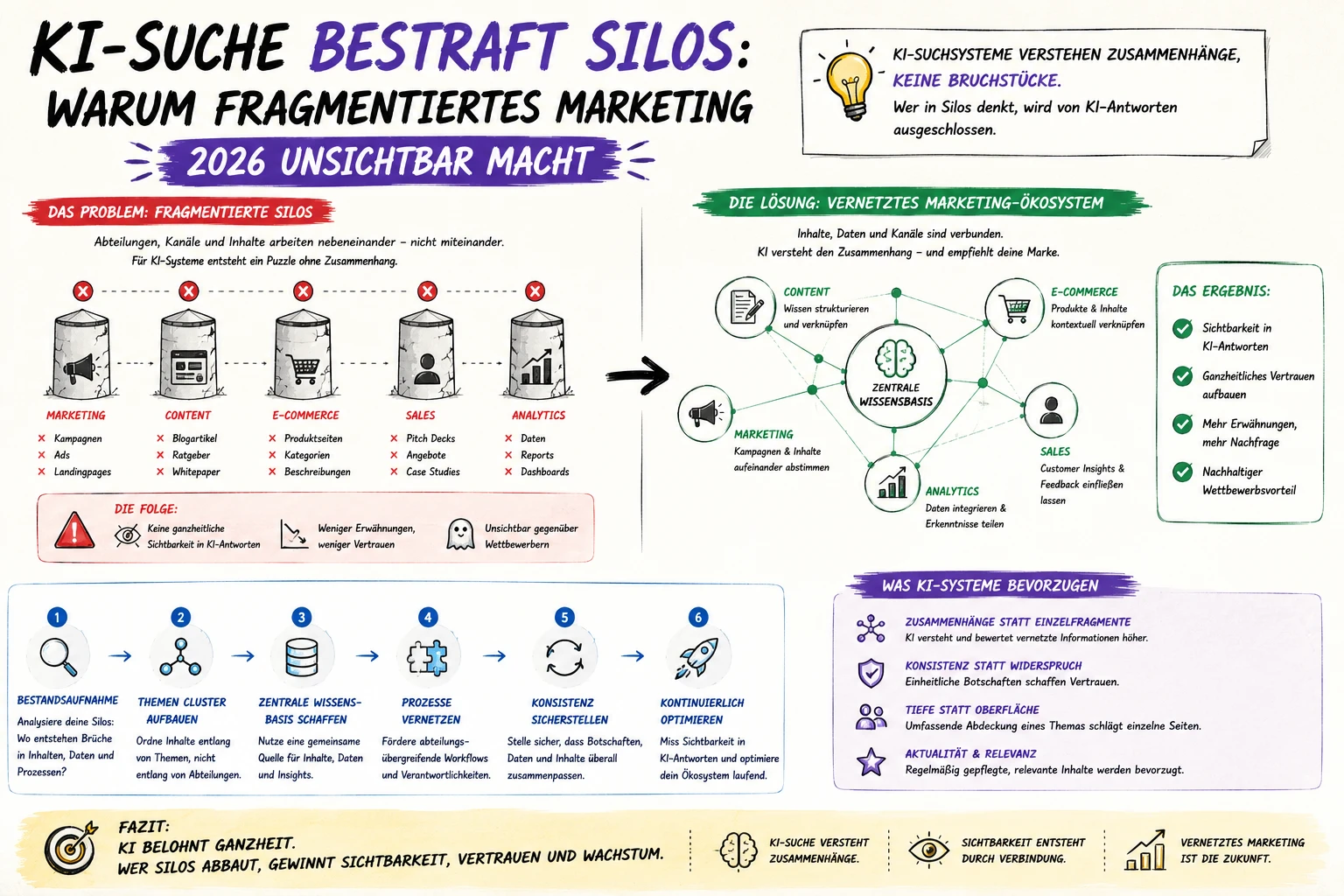
Das N×N-Identitätsproblem
Mit zunehmend mehr KI-Agenten, die eigenständig im Web agieren — nicht nur crawlen, sondern kaufen, buchen, ausfüllen — steigt der Anreiz für Impersonation dramatisch. Ein Agent, der als vertrauenswürdiger Google-Agent durchgeht, bekommt Zugang, den ein unbekannter Agent nicht bekommt. Das heutige System bietet dagegen keinen robusten Schutz.
Was ist Web Bot Auth?
Definition · Web Bot Auth
Web Bot Auth ist ein experimentelles kryptografisches Protokoll zur Authentifizierung von Bot-Anfragen. Statt sich auf selbst gemeldete Header (User-Agent) und IP-Adressen zu verlassen, erlaubt es Bots, ihre HTTP-Anfragen mit einem kryptografischen Schlüssel zu signieren. Websites können diese Signatur gegen den öffentlichen Schlüssel des Bot-Providers verifizieren — ähnlich wie HTTPS-Zertifikate Webseiten-Identitäten beweisen. Das zugrundeliegende Konzept basiert auf dem IETF-Entwurf für HTTP Message Signatures, technisch auch als HTTP Message Signatures Directory bekannt.
Google beschreibt Web Bot Auth offiziell so: Statt ausschließlich auf selbst gemeldete Header und IP-Adressen zu vertrauen, erlaubt Web Bot Auth Agenten, ihre Anfragen kryptografisch zu signieren. Das gibt Website-Betreibern die Möglichkeit, automatisierten Traffic auf ihren Sites zu identifizieren und verhindert, dass andere Akteure versuchen, seriöse Agenten zu imitieren.
Wie funktioniert die kryptografische Signierung?
Web Bot Auth Signierungsprozess: Der Bot signiert jede Anfrage mit seinem privaten Schlüssel. Der Server verifiziert gegen den öffentlichen Schlüssel des Bot-Providers. Da nicht alle Anfragen signiert sind, bleiben klassische Fallback-Methoden nötig.
Der technische Ablauf in vier Schritten:
Bot signiert Anfrage: Der KI-Agent fügt der HTTP-Anfrage eine kryptografische Signatur hinzu, die mit seinem privaten Schlüssel erstellt wurde — zusammen mit Timestamp und Key-ID.
Server empfängt Anfrage: Der Webserver erkennt den Signatur-Header und ruft den öffentlichen Schlüssel des Bot-Providers von dessen Endpoint ab.
Signatur wird verifiziert: Der Server prüft die Signatur gegen den öffentlichen Schlüssel. Bei Erfolg: bestätigte Bot-Identität. Bei Misserfolg: unbekannte oder gefälschte Anfrage.
Zugang basiert auf Identität: Publisher können differenzierte Regeln aufstellen — legitimen Crawlern vollen Zugang geben, unbekannten Anfragen den Zugang verweigern oder einschränken.
Wichtig: Ablaufzeit vs. Cache-Control
Googles Dokumentation weist explizit darauf hin: Das Ablauf-Fenster einer Signatur ist nicht identisch mit dem Cache-Control-Header des Public-Key-Sets. Beide müssen separat validiert werden — ein technisches Detail das bei der Implementierung leicht übersehen wird.
Die drei Vorteile laut Google
Vorteil
Was es bedeutet
Praktische Implikation
Kryptografische Gewissheit
Bot-Identität ist mathematisch beweisbar, nicht nur behauptet
Publisher können sichere Allowlists für legitime Crawler erstellen
Bessere Observability
Klarere Einblicke wie Agenten mit Content interagieren
Differenzierteres Analytics: welcher Bot macht was auf welchen Seiten
Zukunftssicherheit
Aufbau eines Webs wo Agent-Provider und Websites gegenseitiges Vertrauen aufbauen können
Grundlage für differenzierte Zugangspolitiken für verschiedene Agenten
Kurzfassung
Web Bot Auth macht Bot-Identität von „ich behaupte X zu sein" zu „ich kann kryptografisch beweisen, dass ich X bin". Das ist derselbe Sprung wie von HTTP zu HTTPS — von behaupteter zu bewiesener Identität.
Aktueller Status und Einschränkungen
Google ist explizit transparent über den experimentellen Status:
Nur ausgewählte KI-Agenten auf Google-Infrastruktur nutzen Web Bot Auth aktuell
Nicht alle Anfragen dieser Agenten sind signiert
Google signiert noch nicht jede Anfrage eines Agenten der das Protokoll nutzt
Klassische Bot-Verifikation (IP-Check, Reverse-DNS, User-Agent) bleibt weiterhin notwendig
Vorsicht bei zu früher Implementierung
Web Bot Auth darf nicht als primäre Bot-Verifikationsmethode eingesetzt werden. Wer heute Crawler blockt die keine Web-Bot-Auth-Signatur haben, blockt die meisten legitimen Crawler — da das Protokoll noch nicht universell ausgerollt ist.
Das zugrundeliegende Protokoll ist der IETF-Entwurf für HTTP Message Signatures. Es wird von einer Working Group entwickelt, an der sich die Branche beteiligen kann. Das IETF-Mailing-List und ein Feedback-Formular von Google sind verfügbar für Beiträge.
Was das für SEOs und Publisher bedeutet
Kurzfristig (jetzt)
Nichts aktiv unternehmen bezüglich Web Bot Auth — zu früh für produktive Implementierung
Bestehende Bot-Blocking-Probleme beheben: HTTP 429 für legitime Crawler ist heute das drängendere Problem
Dokumentation verfolgen: Googles Developer-Docs zu Web Bot Auth beobachten
Mittelfristig (wenn Standard reift)
Differenzierte Crawler-Politik: Statt einfacher IP-Blocklists können Publisher signaturbasierte Allowlists aufbauen
Bessere GEO-Transparenz: Klar identifizierbare KI-Agenten erlauben präziseres Tracking welche Agenten welche Inhalte nutzen
Bot-Impersonation-Schutz: Signaturbasierte Verifikation reduziert Scraper die legitime Crawler imitieren
Der strategische Blick
Web Bot Auth ist weniger ein SEO-Tool als eine Infrastruktur-Grundlage für agentisches Commerce. In einer Welt wo KI-Agenten im Namen von Nutzern kaufen, buchen und handeln, wird verifizierte Agenten-Identität zur Voraussetzung für Vertrauen. Publisher und Händler werden Policies brauchen: welchen Agenten vertrauen wir welchen Zugang?
Conclusie
Web Bot Auth ist kein Grund zur Panik und kein sofortiger Handlungsbedarf für die meisten SEOs. Es ist ein früher, klarer Hinweis auf die Richtung: Bot-Identität wird kryptografisch, nicht konventionell. Das System, das heute auf User-Agent-Strings und IP-Adressen basiert, ist fundamental unsicher — und mit dem Wachstum von KI-Agenten wird diese Unsicherheit zur echten Schwachstelle.
Web Bot Auth = kryptografische Bot-Signierung, nicht konventionelle Header/IP-Identifikation
Status: Experimentell, nur ausgewählte Google-KI-Agenten, nicht universell
Heute: Klassische Bot-Verifikation weiterhin notwendig als Fallback
Drängenderes Problem: HTTP 429 / 403 für legitime AI-Crawler auf Managed-Hosting
IETF Working Group entwickelt offenen Standard — Industriebeteiligung möglich
Langfristig: Grundlage für differenzierte Crawler-Policies und agentisches Vertrauen im Web
Kernsatz
Web Bot Auth macht für Bot-Identität was HTTPS für Website-Identität gemacht hat: von behauptet zu bewiesen. Das wird nicht über Nacht passieren — aber die Richtung ist gesetzt.
Nächster Schritt: Googles Dokumentation unter developers.google.com/crawling/docs/crawlers-fetchers/web-bot-auth beobachten. Den IETF Working Group Status verfolgen. Heute: bestehende AI-Crawler-Blocking-Probleme beheben.
Autorin: Sophie
SEO-Strategin bei YellowFrog – Schwerpunkte: Technisches SEO, GEO, Bot-Management. Begleitet Unternehmen bei der Vorbereitung auf agentische Bot-Authentifizierung und kryptografische Crawler-Verifikation. Fachlich geprüft von Elena – Head of Strategie & SEO bei YellowFrog
Basierend auf Googles offizieller Web-Bot-Auth-Dokumentation (Mai 2026), dem IETF-Entwurf für HTTP Message Signatures und YellowFrog-Praxisanalysen 2026 zur Crawler-Authentifizierung.
Stand: 14.05.2026. Allgemeine Information, keine Beratung.




.webp)










.webp)



















































.webp)