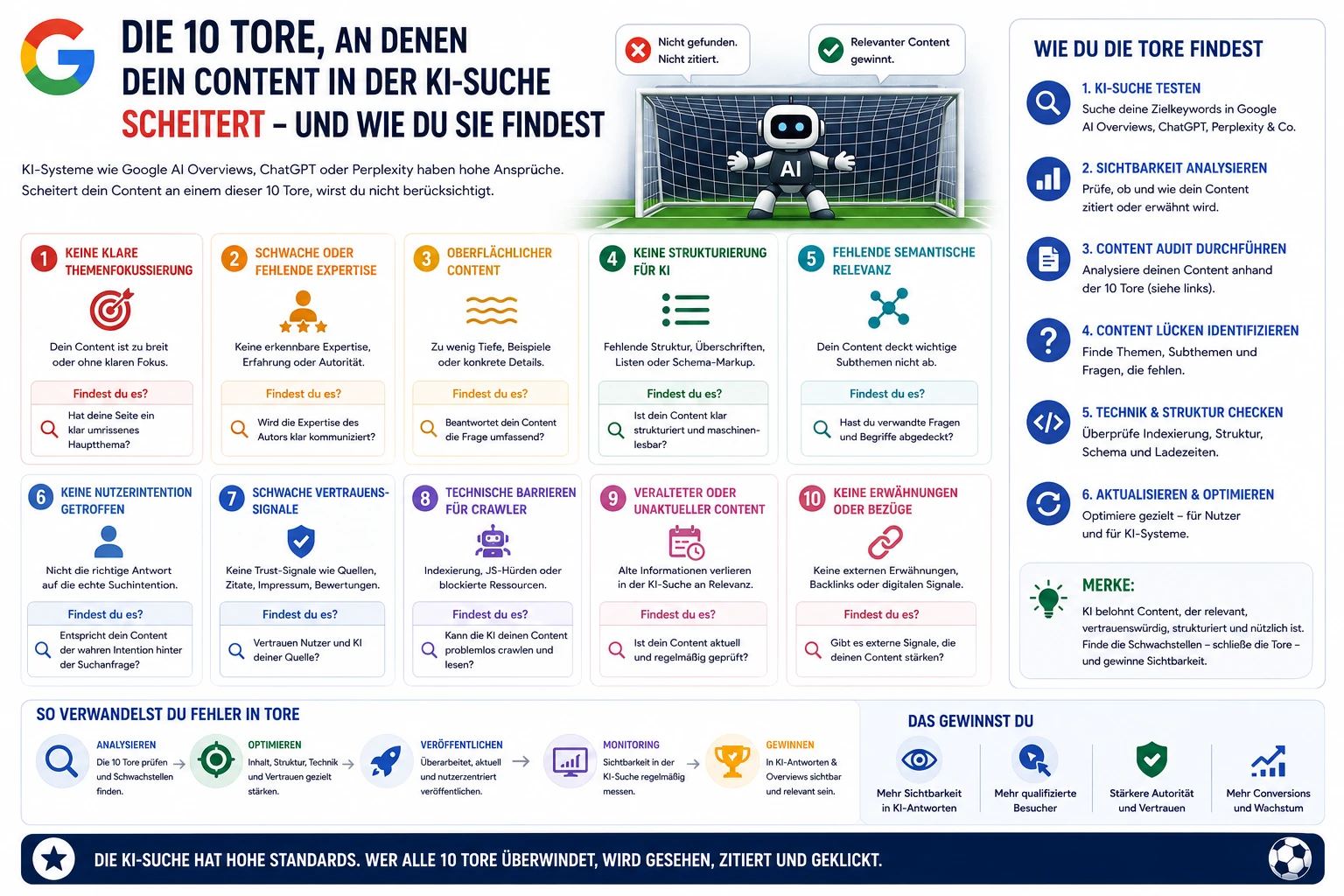
Warum dein WordPress KI-Crawler heimlich blockiert – und deine SEO-Tools schweigen
Deine SEO-Tools zeigen grünes Licht. robots.txt sauber. Kein Penalty. Und trotzdem erscheint deine Site monatelang nicht in KI-Antworten.
Das Szenario ist realer als es klingt. Managed-WordPress-Hosts, WAF-Layer und Cloudflare-Konfigurationen können GPTBot, ClaudeBot und OAI-SearchBot mit HTTP 429 oder 403 blockieren – völlig unsichtbar für klassische SEO-Monitoring-Tools. Der Block feuert lautlos. Die fehlenden Citations zeigen sich Monate später in GEO-Dashboards, die niemand direkt mit dem ursprünglichen Problem verbindet.
ClaudeBot-Crawl-Requests pro Referral sind extrem hoch – einer der Gründe warum Hosts AI-Crawler abwehren
Branchenbeobachtung 2026
Gap
Google AI Mode Citation-Präsenz fällt deutlich auch bei Sites mit gutem Googlebot-Zugang – Platform-Blocks sichtbar
Praxisbeobachtung YellowFrog
429
HTTP-Statuscode den Managed-Hosts für AI-Crawler auf Cache-Miss-Requests senden – unsichtbar für SEO-Tools
Server-Log-Analyse
≠ 403
Die Ursache ist nicht immer WAF oder robots.txt – Platform-Level-Blocks liegen eine Schicht tiefer
Branchenbeobachtung
Executive Summary
Managed-WordPress-Hosts setzen Platform-Level-Schutzmechanismen ein, die KI-Crawler als potenzielle Scraper behandeln. Die Blocks liegen unterhalb von Cloudflare und Security-Plugins – und sind deshalb für klassische SEO-Monitoring-Tools unsichtbar. Cache-Hits geben HTTP 200, Cache-Misses geben 429: Dasselbe User-Agent, dieselbe Site, zwei verschiedene Outcomes.
Die Konsequenz ist direkt: Crawl-Zugang korreliert direkt mit Citation-Präsenz. Wenn die Plattform AI-Crawler blockiert, verschwinden Citations – nicht wegen mangelnder Content-Qualität, sondern wegen fehlenden Zugangs. Diagnose, nicht Content-Optimierung, ist der erste Schritt.
Geprüft: Mai 2026 · Nächste Prüfung: Q3 2026Das Problem ist nicht sichtbar – bis es in fehlenden KI-Citations auftaucht. Managed WordPress kann AI-Crawler blockieren ohne dass klassische SEO-Tools einen Alert senden.
Das unsichtbare Problem: Warum SEO-Tools schweigen
Klassische SEO-Monitoring-Tools prüfen Crawler-Zugang aus einer User-Perspektive oder mit Googlebot-User-Agent. Sie prüfen nicht, ob GPTBot, ClaudeBot oder OAI-SearchBot HTTP 200, 429 oder 403 bekommen. Das ist die Lücke.
Wenn ein Managed-WordPress-Host einen Platform-Level-Block für AI-Crawler aktiviert, passiert Folgendes:
Googlebot: voller Zugang → klassisches SEO unauffällig
GPTBot: 429 auf Cache-Misses → ChatGPT: keine Citations für neue/aktualisierte Inhalte
ClaudeBot: 429 auf Cache-Misses → Claude: keine Citations
SEO-Tool-Check: Alles grün – kein Crawling-Problem erkannt
Das zeitverzögerte Signal
Der Block feuert im Mai. Fehlende Citations zeigen sich im GEO-Dashboard im August. Niemand verbindet das zurück zum Platform-Block vom Mai. Der Fehlschluss: „Unser Content wird nicht zitiert, weil er nicht gut genug ist." Die Wahrheit: Er wird nicht zitiert, weil der Crawler ihn nicht abrufen kann.
Merksatz: Die Platform-by-Platform-Aufteilung in Citations entspricht direkt der Platform-by-Platform-Aufteilung im Crawl-Zugang. Das ist kein Zufall – es ist Kausalität. Wer AI-Crawler blockiert, blockiert AI-Citations.
Die drei Blocking-Schichten
AI-Crawler-Blocks können auf drei verschiedenen Ebenen entstehen – jede mit anderen Diagnose- und Lösungsansätzen:
1
Platform-Level des Managed-Hosts Unsichtbar
WP Engine, Kinsta, Pressable und ähnliche Hosts setzen Server-Level-Regeln ein, die AI-Crawler als Scraper klassifizieren. HTTP 429 auf Cache-Misses. Cloudflare und Security-Plugins sind nicht die Ursache. Der Block liegt tiefer. Diagnose nur über Server-Logs und direktes Support-Ticket.
2
WAF und CDN (Cloudflare) Sichtbar im Dashboard
Cloudflares „Block AI Bots"-Toggle, Super Bot Fight Mode und WAF Custom Rules können AI-Crawler blockieren. Auch wenn „Block AI Bots" deaktiviert ist: Custom Rules, die „definitely automated" Traffic challengen, können AI-Crawler erfassen. Cloudflare Dashboard → Security → Bots → AI Crawl Control.
3
Security-Plugin und robots.txt Prüfbar
WordPress Security-Plugins (Wordfence, Sucuri) haben eingebaute Bot-UA-Blocklists. robots.txt mit „bot" als Disallow-Muster blockt alle benannten Crawler unbeabsichtigt. Beide sind prüfbar und direkt korrigierbar.
Drei Schichten, drei verschiedene Diagnose-Ansätze. Ein sauberes Cloudflare-Dashboard bedeutet nicht, dass Platform-Level-Blocks ausgeschlossen sind.
Das Cache-Miss-Problem: Warum curl lügt
Cache-Miss-Block
Ein Cache-Miss-Block tritt auf, wenn ein Managed-Host gecachte Seiten (Cache-Hits) mit HTTP 200 ausliefert, unkacachte Seiten (Cache-Misses) aber mit HTTP 429 blockiert. Dasselbe User-Agent, dieselbe Domain, zwei verschiedene Outcomes. Das erklärt, warum ein einfacher curl-Test auf die Homepage 200 zeigt – aber der tatsächliche Crawler auf einem signifikanten Teil der Site geblockt wird. Neue Inhalte, frisch aktualisierte Seiten und seltener besuchte URLs sind besonders betroffen.
Das Muster zeigt sich in Server-Log-Analysen immer wieder: In einem 24-Stunden-Zeitraum kommt ein Teil der ClaudeBot-Requests mit HTTP 200 zurück (Cache-Hits) und ein anderer Teil mit HTTP 429 (Cache-Misses). Gleicher User-Agent, gleiche Site, zwei Outcomes – abhängig allein davon, ob die angeforderte URL gerade im Cache liegt.
Cache-Hits geben 200, Cache-Misses geben 429 – dasselbe ClaudeBot-User-Agent auf derselben Site. Der einfache curl-Test auf die Homepage zeigt nur die linke Seite.
Ein curl-Test auf die Startseite ist notwendig, aber nicht ausreichend. Die Startseite ist fast immer gecacht. Neue Blogposts und Long-tail-URLs sind am häufigsten betroffen.
Crawl-Ratio: Warum Hosts AI-Crawler blockieren
Die Crawl-to-Referral-Ratio erklärt, warum Hosting-Infrastruktur begonnen hat, AI-Crawler abzuwehren. Verschiedene Crawler erzeugen sehr unterschiedliche Server-Last für sehr unterschiedlichen Traffic-Return:
Crawler
Crawl-zu-Referral-Verhältnis
Charakterisierung
Google
Niedrig
Effizient – hoher Referral-Return
Perplexity
Mittel
Noch vertretbar
GPTBot
Hoch
Training ohne Referral-Return
ClaudeBot
Sehr hoch
Massive Server-Last, minimaler Return
Aus Hosting-Perspektive rational: ClaudeBot erzeugt deutlich mehr Requests als andere Crawler – aber nur einen Bruchteil davon führt zu Referral-Traffic. Massive Server-Last ohne entsprechenden Traffic-Gegenwert. Ob das die richtige Entscheidung für die eigene Site ist, ist eine separate Frage.
Wichtige Unterscheidung: Echter ClaudeBot vs. Spoofed UA
In Server-Log-Analysen zeigt sich häufig: Ein erheblicher Teil des vermeintlichen ClaudeBot-Traffics stammt nicht aus Anthropics offiziellen AWS-IP-Ranges – sondern aus anderen Cloud-Infrastrukturen. Sehr wahrscheinlich Scraper, die sich als ClaudeBot ausgeben. Ein Teil der 429-Blocks auf vermeintlichen AI-Crawlern könnte legitimes Impersonation-Blocking sein – kein Versehen, sondern korrektes Verhalten. Prüfe die IP-Ranges bei der Diagnose.
AI-Crawler User-Agents: Training vs. Search
Training-Crawler vs. Search-Crawler
Training-Crawler sammeln Daten für LLM-Modelltraining (GPTBot, CCBot, Google-Extended, Applebot-Extended). Search-Crawler holen Inhalte in Echtzeit für KI-Suchanfragen (OAI-SearchBot, ChatGPT-User, ClaudeBot, PerplexityBot). Wer Training-Crawler blockiert, schützt Inhalte vor Trainingsdaten-Nutzung. Wer Search-Crawler blockiert, blockiert KI-Suchergebnisse. Beide dürfen nie mit einem einzigen Disallow-Muster zusammengefasst werden.
User-Agent
Typ
Betreiber
Empfehlung
OAI-SearchBot
Search
OpenAI
Erlauben – ChatGPT-Suche
ChatGPT-User
Search
OpenAI
Erlauben – ChatGPT-Browsing
GPTBot
Training
OpenAI
Eigene Entscheidung – Training-Daten
ClaudeBot
Search & Training
Anthropic
Erlauben – Claude-Suche
anthropic-ai
Training
Anthropic
Eigene Entscheidung
PerplexityBot
Search
Perplexity
Erlauben
Google-Extended
Training
Google
Eigene Entscheidung – Gemini
Applebot-Extended
Training
Apple
Eigene Entscheidung
CCBot
Training
Common Crawl
Eigene Entscheidung
Die kritische Unterscheidung: GPTBot und OAI-SearchBot nie gemeinsam blockieren. Wer GPTBot blockiert (Training), muss OAI-SearchBot explizit erlauben (Search) – sonst ist die Site unsichtbar für ChatGPT-Suchergebnisse.
Diagnose: 5 Schritte um den Block zu finden
1
curl-Test mit AI-Crawler-User-Agents
Den User-Agent simulieren und Response-Code prüfen:
# GPTBot testen
curl -A 'GPTBot' https://yourdomain.com/ -I
# ClaudeBot testen
curl -A 'ClaudeBot' https://yourdomain.com/ -I
# OAI-SearchBot testen
curl -A 'OAI-SearchBot' https://yourdomain.com/ -I
200: Zugang frei (aber: könnte Cache-Hit sein). 429: Rate-Limit-Block. 403: WAF-Block. Mehrere URLs testen – nicht nur die Homepage.
Kurzfassungcurl allein reicht nicht. Homepage gibt fast immer 200 (Cache-Hit). Auch neue Artikel-URLs und seltener besuchte Seiten testen.
2
Server-Logs auf 429-Muster für AI-User-Agents prüfen
Wenn curl 200 zeigt, aber Server-Logs 429 für AI-User-Agents zeigen: Cache-Miss-Problem auf Platform-Level. Server-Access-Logs filtern nach User-Agent und HTTP-Status:
Bei Managed-Hosts: Support-Ticket mit der Bitte um Log-Einsicht oder Zugang zum Hosting-Panel.
Kurzfassung429 im Server-Log bei AI-User-Agents = Platform-Level-Block bestätigt. Das ist der Beweis für das Support-Ticket.
3
Cloudflare Dashboard: AI Crawl Control und WAF
Cloudflare Dashboard → Security → Bots → AI Crawl Control. Prüfen: Ist „Block AI Bots" aktiv? Welche individuellen Bots sind geblockt? Super Bot Fight Mode-Einstellungen: Wenn „definitely automated" gechallenged wird, erfasst das auch AI-Crawler. WAF Custom Rules auf AI-User-Agent-spezifische Regeln durchsuchen.
Kurzfassung„Block AI Bots" deaktiviert allein reicht nicht. WAF Custom Rules und Super Bot Fight Mode separat prüfen.
4
Hosting-Panel und Support-Ticket für Platform-Level-Block
Für WP Engine: Utilities → Redirect Bots (muss aus sein) + Web Rules (keine AI-UA-Blocks). Dann Support-Ticket mit konkreter Beschreibung:
"Wir haben über curl reproduziert, dass Requests mit
ClaudeBot/GPTBot User-Agent-Strings HTTP 429 erhalten
für Cache-Miss-Requests in unserer Umgebung.
Cloudflare und Security-Plugins sind nicht die Ursache.
Handelt es sich um ein Platform-Level
AI-Crawler-Mitigation-Feature?
Kann es deaktiviert oder per-Bot konfiguriert werden?"
Andere Hosts: Security-Sektion im Dashboard + analoges Ticket.
KurzfassungKonkretes Support-Ticket mit curl-Beweis. Nicht vage fragen – spezifischen HTTP-Status und User-Agent benennen.
5
robots.txt live prüfen und korrigieren
https://yourdomain.com/robots.txt live abrufen. Achtung: Die live-ausgelieferte Datei kann von der Datei im WordPress-Backend abweichen – CDN-Cache oder Hosting-Panel können eine andere Version ausliefern. Auf unbeabsichtigte Muster prüfen: Disallow: / für alle Bots, bot als generisches Disallow-Pattern das alle named Crawler trifft.
KurzfassungLive-robots.txt fetchen und mit Backend-Datei vergleichen. CDN-Caching kann eine andere Version ausliefern als erwartet.
Der Fix: Was wo eingestellt werden muss
Problem-Ursache
Wo fixen
Konkrete Maßnahme
Platform-Level-Block (429)
Hosting-Support-Ticket
Support mit curl-Beweis kontaktieren, Platform-Level-Mitigation deaktivieren lassen
Cloudflare „Block AI Bots"
Cloudflare Dashboard
Security → Bots → AI Crawl Control → Block AI Bots deaktivieren oder per-Bot konfigurieren
Cloudflare WAF Custom Rule
Cloudflare Dashboard
Security → WAF → Custom Rules → AI-UA-spezifische Rules finden und entfernen oder Skip-Action hinzufügen
„bot" als Disallow-Pattern entfernen, AI-Crawler explizit erlauben
robots.txt richtig konfigurieren für AI-Crawler
Die robots.txt sollte Search-Crawler explizit erlauben und Training-Crawler separat behandeln. Niemals beides mit einem einzigen Muster zusammenfassen:
Wichtig: WAF überschreibt robots.txt
WAF- und CDN-Regeln werden vor robots.txt ausgewertet. Ein WAF-Block überschreibt jede robots.txt-Allow-Direktive. Eine saubere robots.txt allein garantiert keinen Crawler-Zugang wenn WAF-Regeln blockieren.
Häufige Fragen
Warum blockiert mein managed WordPress GPTBot und ClaudeBot ohne dass ich es bemerke?
Managed-Hosts setzen Platform-Level-Blocks ein, die AI-Crawler als Scraper behandeln. Die Blocks feuern auf Server-Level, bevor Cloudflare oder Security-Plugins eingreifen. SEO-Tools prüfen keine AI-User-Agent-Responses. Der Block ist unsichtbar bis fehlende GEO-Citations Monate später sichtbar werden.
Was bedeutet HTTP 429 für AI-Crawler?
HTTP 429 bedeutet Rate Limit überschritten – für AI-Crawler ein effektiver Block. Der Crawler kann die Seite nicht abrufen und zitiert die Quelle nicht. Besonders heimtückisch: Cache-Hits geben 200, Cache-Misses geben 429. Ein einfacher curl-Test zeigt deshalb oft 200, obwohl der tatsächliche Crawler geblockt wird.
Wie unterscheiden sich GPTBot und OAI-SearchBot?
GPTBot ist OpenAIs Training-Crawler für LLM-Training. OAI-SearchBot ist OpenAIs Search-Crawler für ChatGPT-Suchanfragen in Echtzeit. Wer GPTBot blockiert, blockiert Training-Daten. Wer OAI-SearchBot blockiert, blockiert ChatGPT-Suchergebnisse. Beide separat in robots.txt und WAF behandeln.
Wie prüfe ich ob mein WordPress AI-Crawler blockiert?
Schritt 1: curl -A 'GPTBot' https://yourdomain.com/ -I ausführen. Schritt 2: Server-Logs auf 429-Einträge für AI-User-Agents prüfen. Schritt 3: Cloudflare Dashboard → Security → Bots → AI Crawl Control. Schritt 4: Hosting-Panel auf Platform-Level-Blocks prüfen. Schritt 5: robots.txt live abrufen auf unbeabsichtigte Bot-Disallow-Muster.
Überschreibt WAF die robots.txt?
Ja. WAF- und CDN-Regeln werden vor robots.txt ausgewertet. Ein WAF-Block überschreibt jede robots.txt-Allow-Direktive. Eine saubere robots.txt allein garantiert keinen Crawler-Zugang wenn WAF-Regeln blockieren. Beide Layer separat prüfen und konfigurieren.
Conclusie
Crawl-Zugang und Citation-Präsenz sind direkt korreliert. Wenn die Plattform blockiert, verschwinden Citations – unabhängig von Content-Qualität oder Schema. Diagnose kommt vor Content-Optimierung.
Platform-Level-Blocks bei Managed-Hosts blockieren AI-Crawler mit HTTP 429 ohne SEO-Tool-Alert.
Cache-Miss-Problem: Cache-Hits geben 200, Cache-Misses geben 429. curl auf die Homepage reicht als Diagnose nicht aus.
Crawl-zu-Referral-Verhältnis bei ClaudeBot und GPTBot ist deutlich höher als bei Google – das erklärt, warum Hosts AI-Crawler abwehren.
Drei Blocking-Schichten: Platform-Level, WAF/Cloudflare, Security-Plugin/robots.txt. Jede separat diagnostizieren.
GPTBot ≠ OAI-SearchBot: Training vs. Search separat behandeln. Nie beide gemeinsam blockieren.
WAF überschreibt robots.txt: Eine saubere robots.txt allein garantiert keinen Crawler-Zugang.
Support-Ticket mit curl-Beweis ist der direkte Weg bei Platform-Level-Blocks auf Managed-Hosts.
Kernsatz
AI-Crawler-Zugang im Jahr 2026 als optional zu behandeln, ist dieselbe Entscheidung wie organische Suche im Jahr 2008 als optional zu behandeln. Es hat eine Weile funktioniert. Dann nicht mehr. Die Diagnose dauert eine Stunde. Der Schaden durch jahrelange unsichtbare Blockierung ist schwerer rückgängig zu machen.
Nächster Schritt: Jetzt: curl -A 'GPTBot' https://yourdomain.com/ -I ausführen. Dann dieselbe Abfrage für 3–5 unterschiedliche Seiten (Blogposts, Unterseiten, nicht nur Homepage). HTTP 429 bei irgendeiner → Schicht-2-Diagnose (Cloudflare) und Schicht-1-Diagnose (Hosting-Support) starten.
Autorin: Sophie
SEO-Strategin bei YellowFrog – Schwerpunkte: Technisches SEO, GEO, AI-Crawler-Diagnose. Begleitet Unternehmen bei der Sicherung des Crawler-Zugangs für KI-Suchsysteme. Fachlich geprüft von Elena – Head of Strategie & SEO bei YellowFrog
Basierend auf YellowFrog-Praxisanalysen 2024–2026 zu AI-Crawler-Diagnose, Server-Log-Auswertungen bei Managed-WordPress-Installationen und Branchenbeobachtungen.
Stand: 14.05.2026. Keine Rechtsberatung.
Rechtlicher Hinweis (Stand: 14.05.2026): Allgemeine Information. Hosting-Konfigurationen ändern sich laufend.
AI-Crawler-Zugang prüfen und sichern
Wir diagnostizieren ob GPTBot, ClaudeBot und OAI-SearchBot eure Site erreichen und beheben unsichtbare Blocks.





.webp)










.webp)



















































.webp)