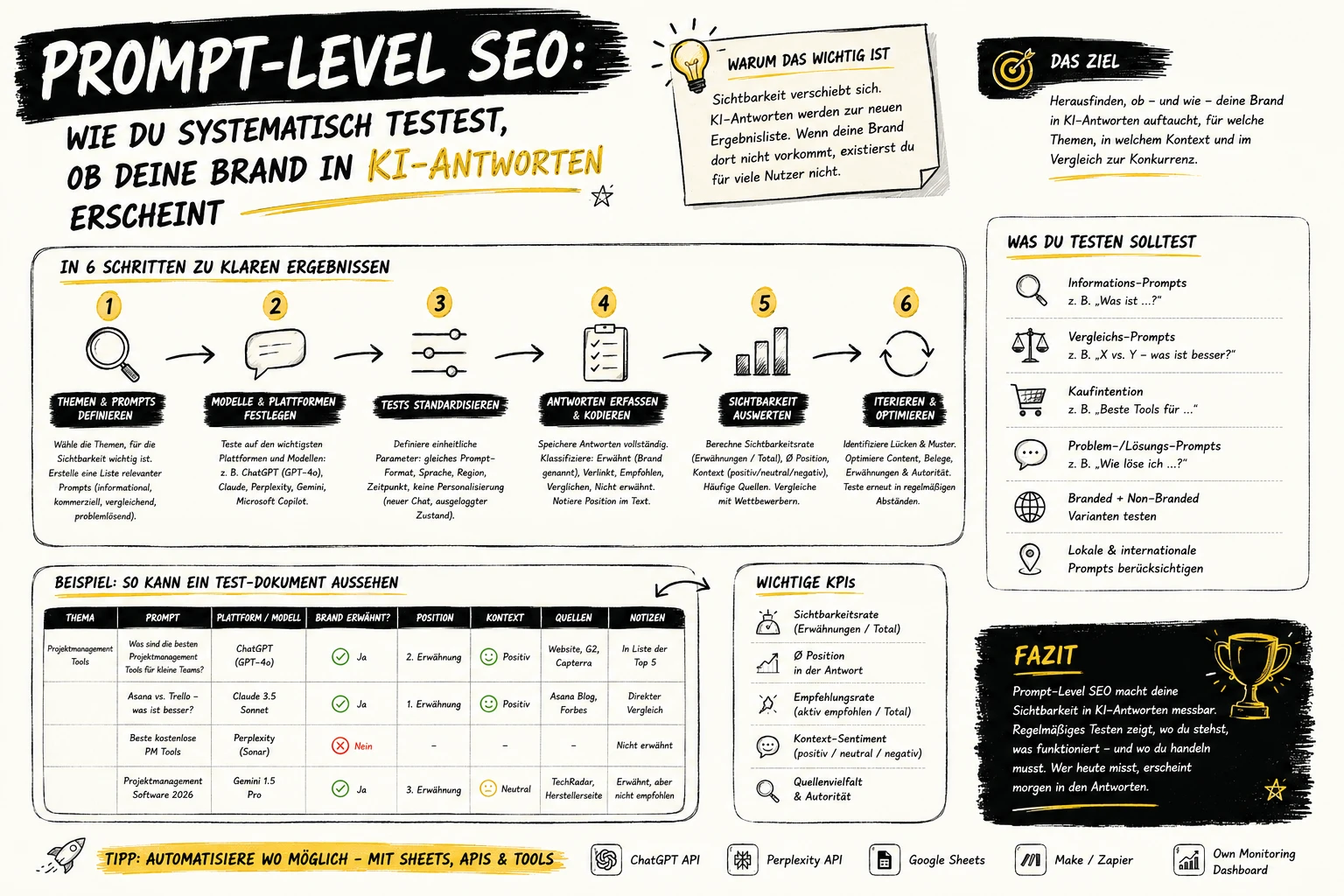
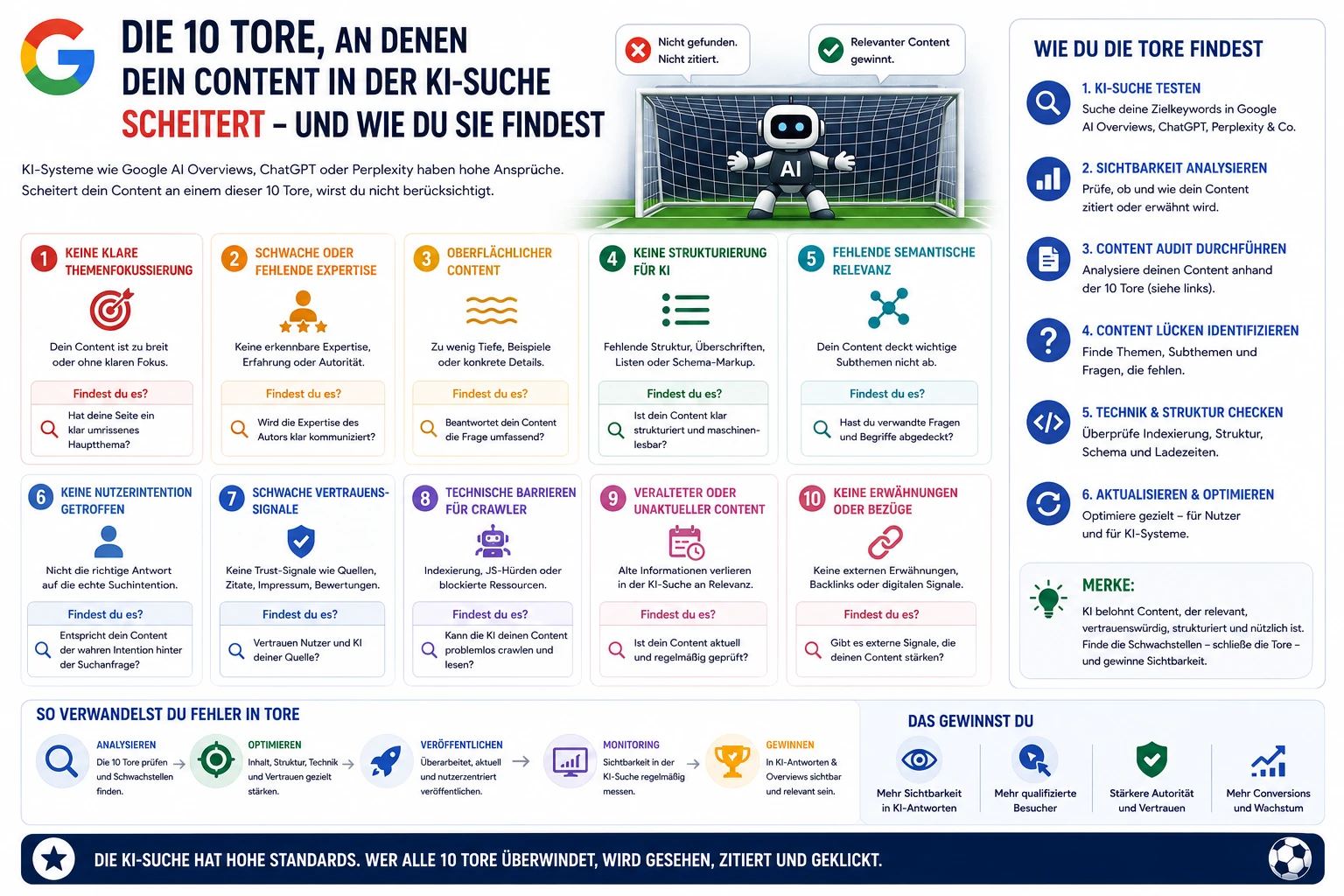
Prompt-Level SEO: Wie du systematisch testest ob deine Brand in KI-Antworten erscheint
Sophie
May 17, 2026
Wie teste ich ob meine Brand in ChatGPT, Perplexity und Gemini erscheint? Das Experiment-Framework für Prompt-Level SEO – mit Hypothesenstruktur, Messmethoden und Dokumentations-Standards.
Prompt-Level SEO: Wie du systematisch testest ob deine Brand in KI-Antworten erscheint
Es gibt unzählige Empfehlungen wie man LLM-Sichtbarkeit verbessert. Viele davon sind Annahmen. Was tatsächlich funktioniert — für die eigene Industrie und Brand — lässt sich nur durch strukturierte Experimente herausfinden. Prompt-Level SEO ist die Disziplin, systematisch zu testen welche Content-Änderungen die Inclusion-Rate und Position in KI-Antworten beeinflussen.
Das Kernproblem: LLM-Sichtbarkeit lässt sich nicht wie klassische Rankings mit einem Screenshot eines Rank-Trackers messen. LLMs sind nicht deterministisch, variieren nach Nutzer, Kontext und Zeitpunkt, und werden regelmäßig upgedated. Ohne Experimentier-Framework entsteht kein verlässliches Wissen — nur Anekdoten.
Variable pro Experiment — die wichtigste Regel: nie zwei Dinge gleichzeitig ändern
Quelle: Jason Tabeling / SEL, Mai 2026
7 Tage
Mindest-Messzeitraum pro Experiment — LLMs bewegen sich mit unterschiedlicher Geschwindigkeit
Quelle: Jason Tabeling / SEL, Mai 2026
3 KPIs
Inclusion Rate, Position-in-Response, Sentiment/Framing — jeder Experiment-Run trackt alle drei
Quelle: Jason Tabeling / SEL, Mai 2026
API
Synthetisches Testing über API eliminiert Personalisierungs-Bias — Standard für zuverlässige Resultate
Quelle: Jason Tabeling / SEL, Mai 2026
Executive Summary
Prompt-Level SEO braucht dasselbe wissenschaftliche Mindset wie klassische SEO-Experimente: eine klar isolierte Variable, einen definierten Messzeitraum, dokumentierte Hypothesen und wiederholbare Testumgebungen. Drei Experiment-Typen sind besonders wirkungsvoll: Content-Modifikationen (Single-Paragraph-Swap), Schema-Testing (FAQ-Schema-Isolation), und Prompt-Bibliotheken für konsistentes Baseline-Measurement. Das Ziel ist nicht ein One-off-Win — sondern ein repeatable Framework das mit LLM-Updates Schritt hält.
Klassische SEO hat ein klares Feedback-Loop: Änderung implementieren → Rankings beobachten → Kausalität ableiten (mit Vorsicht). LLM-Sichtbarkeit hat diesen Loop nicht — zumindest nicht ohne bewusstes Experiment-Design.
Die Herausforderungen sind real:
LLMs sind nicht deterministisch — dieselbe Frage gibt verschiedene Antworten
Personalisierung beeinflusst Antworten — ohne Kontrolle kein sauberes Signal
Modell-Updates verändern die Baseline — ohne Versionierung keine Vergleichbarkeit
Änderungseffekte sind verzögert — LLMs indizieren nicht in Echtzeit
Definition · Prompt-Level SEO Experiment
Ein Prompt-Level SEO Experiment ist ein strukturierter Test, der isoliert misst wie eine spezifische Content- oder Schema-Änderung die Inclusion Rate, Position-in-Response oder das Sentiment-Framing einer Brand in LLM-Antworten beeinflusst. Grundvoraussetzung: Isolation einer einzigen kausalen Variable, dokumentierte Hypothese, definierten Messzeitraum und kontrollierte Testumgebung.
Die vier Grundprinzipien des Prompt-Level SEO
Prinzip
Was es bedeutet
Typischer Fehler
1 Variable isolieren
Pro Experiment nur eine Änderung — Content ODER Schema, nie beides
Produktbeschreibung + Schema gleichzeitig ändern → keine Attribution möglich
If-Then-Because
Hypothese vor dem Test: Wenn X, dann Y, weil Z
Ad-hoc-Interpretation nach dem Ergebnis → Confirmation Bias
Version Control
Modell + Version beim Testen dokumentieren
Modell-Update verändert Baseline, aber kein Vergleichspunkt vorhanden
API / Synthetisch
Über API testen statt Browser um Personalisierung zu eliminieren
Personalisiertes Ergebnis als generelle Sichtbarkeit interpretieren
Das häufigste Experiment-Problem
Zu viel auf einmal ändern. Ein Content-Update das gleichzeitig Produktbeschreibung, FAQ-Antwort und Schema modifiziert, kann im besten Fall zeigen ob die Brand besser oder schlechter sichtbar ist — aber nicht warum. Ohne diese Attribution ist das Experiment wertlos für zukünftige Entscheidungen.
Das wirkungsvollste Content-Experiment: Ein einzelner, zielgenauer Textabschnitt wird geändert. Nicht die gesamte Seite. Nicht mehrere Abschnitte. Ein Paragraph.
ASetup
Kontrollseite: originaler Content. Testseite: modifizierter Paragraph (z.B. verbesserter Produktbeschreibungs-Paragraph). Prompt: gezielt auf die geänderte Information ausgerichtet. Messung: Inclusion Rate und Position-in-Response über 7 Tage.
BHypothesen-Struktur
Wenn: wir den Produktbeschreibungs-Paragraph auf Seite X
von vagen Adjektiven auf konkrete Messwerte umschreiben
Dann: steigt die Brand-Inclusion-Rate bei der Prompt-Query
"Welche Tools helfen bei [spezifisches Problem]"
Weil: LLM-Systeme konkrete, verifizierbare Fakten bevorzugen
gegenüber Marketing-Sprache
CWarum es funktioniert
Der Single-Paragraph-Swap erzeugt maximale Isolierung. Der Prompt ist direkt auf die geänderte Information ausgerichtet — was eine direkte Attributions-Möglichkeit gibt. Wenn die Inclusion Rate nach der Änderung steigt, ist der kausale Zusammenhang klar.
Schema-Experimente brauchen vollständige Isolation: Die Schema-Änderung muss die einzige Variable sein. Kein Ändern von sichtbarem HTML-Text gleichzeitig.
ABesonders effektives Experiment: FAQ-Schema zu bestehenden Q&A-Abschnitten hinzufügen
Seiten die bereits Q&A-Abschnitte im HTML haben bekommen FAQ-Schema. Der sichtbare Text bleibt exakt gleich — nur das JSON-LD wird hinzugefügt. Forschung zeigt: Das erleichtert LLMs das Ingestieren dieser Abschnitte. Das Schema macht die Frage-Antwort-Beziehung explizit.
BZu testende Schema-Properties
Brand, Model, Offer-Details zu Produkt-Schema hinzufügen ohne sichtbaren Text zu ändern
FAQPage zu Seiten mit Q&A-Content hinzufügen (als separates Experiment zu Punkt A)
Author- und Organization-Markup auf Artikel-Seiten testen
Die Baseline-Challenge bei Schema-Tests:
Schema-Änderungen brauchen eine strenge Baseline-Phase bevor die Änderung implementiert wird. Mindestens 7 Tage Baseline-Messung, dann Änderung, dann erneut 7+ Tage Messung. Nur so ist Attribution möglich.
Messung und Dokumentation
Drei KPIs für jeden Experiment-Run:
KPI
Was gemessen wird
Wie gemessen
Inclusion Rate
Wird die Brand in X% der Prompt-Antworten erwähnt?
N Prompts → Anzahl Mentions / N = Inclusion Rate
Position-in-Response
Wo in der Antwort erscheint die Brand? Erste Empfehlung? Leader? Supporting?
Position 1–N in der generierten Antwort tracken
Sentiment / Framing
Wie wird die Brand beschrieben? Positiv, neutral, eingeschränkt?
Qualitative Kategorisierung per Antwort
Dokumentations-Standard: Jeder Test wird mit If-Then-Because-Hypothese archiviert. Das dokumentiert Prämisse, Aktion und erwartetes Outcome — und erlaubt zukünftigen Teams zu validieren ob ein Test noch relevant ist nachdem LLMs sich weiterentwickelt haben.
Version Control ist nicht optional. Wenn ein Modell-Update die Baseline verändert — was regelmäßig passiert — muss dokumentiert sein welches Modell und welche Version beim Test genutzt wurde. Ohne das ist kein sinnvoller Vergleich möglich.
Testumgebung richtig einrichten
Browser-Cache immer leeren bevor Prompts gemessen werden
Kein Login-State beim Testing — Personalisierung eliminieren
API-Zugang bevorzugen wo verfügbar — API-Antworten haben weniger Personalisierungs-Bias als Browser-Interfaces
Synthetische Testing-Plattformen für skalierbare Tests nutzen wo möglich
Prompt-Bibliothek pflegen: Jede Prompt-Query wird mit Timestamp und Modell-Version gespeichert für spätere Vergleiche
Prompt-Bibliothek
Eine Prompt-Bibliothek ist ein zeitgestempeltes Repository der exakten Prompt-Queries die für Baseline und Messung verwendet wurden. Sie enthält: Inclusion Rate, Position-in-Response und Sentiment/Framing für jede Query. Sie ist die einzige Möglichkeit, Ergebnisse über Zeit und Modell-Updates hinweg vergleichbar zu halten.
Vorsicht bei Modell-Updates
LLM-Updates können die Baseline verändern ohne dass irgendeine Content-Änderung stattgefunden hat. Ein Test der letzte Woche eine Verbesserung zeigte, kann diese Woche nach einem Modell-Update wieder auf Baseline liegen — nicht weil die Content-Änderung rückgängig gemacht wurde, sondern weil das Modell selbst sich geändert hat. Modell-Versionierung ist deshalb kein optionales Detail.
Conclusie
Prompt-Level SEO ist kein Hype — es ist die konsequente Anwendung des wissenschaftlichen Methode auf ein neues Optimierungsfeld. Die Tools sind andere, die Grundprinzipien sind dieselben: Isolieren, messen, dokumentieren, wiederholen.
1 Variable pro Experiment: Content-Änderung ODER Schema-Änderung, nie beides.
If-Then-Because: Hypothese vor dem Test dokumentieren, nicht nach dem Ergebnis interpretieren.
7+ Tage messen: LLMs bewegen sich mit verschiedenen Geschwindigkeiten.
Version Control: Modell + Version immer dokumentieren — Updates verändern Baselines.
API-Testing: Personalisierungs-Bias eliminieren für zuverlässige Signale.
Drei KPIs: Inclusion Rate, Position-in-Response, Sentiment/Framing.
Prompt-Bibliothek: Einzige Möglichkeit für zeitliche Vergleichbarkeit.
Kernsatz
Es gibt Unmengen Empfehlungen wie man LLM-Sichtbarkeit verbessert. Was tatsächlich für die eigene Industrie und Brand funktioniert, lässt sich nur durch Experimente herausfinden. Hypothesen-getriebenes Testing ist der Weg — nicht Annahmen.
Erster Schritt: Die drei häufigsten Queries definieren für die die eigene Brand in ChatGPT oder Perplexity erscheinen soll. Baseline-Inclusion-Rate messen (7 Tage). Erste If-Then-Because-Hypothese formulieren. Dann: eine Variable ändern.
Autorin: Sophie
SEO-Strategin bei YellowFrog (GEO, LLM-Testing, KI-Sichtbarkeit). Blog - FAQ - LinkedIn - YouTube Review: Elena – Head of SEO
Quellen: Jason Tabeling / Search Engine Land (8. Mai 2026) · YellowFrog-Analysen 2024–2026.
Mai 2026. Allgemeine Information, keine Beratung.
Rechtlicher Hinweis (Stand: Mai 2026): Allgemeine Information zu LLM-Testing-Methoden. LLM-Modelle, APIs und Verhalten entwickeln sich laufend weiter — Testergebnisse können nicht garantiert werden. Keine Rechts- oder Methodenberatung.
Prompt-Level-SEO-Framework aufsetzen
Wir definieren deine Prompt-Bibliothek, messen deine Baseline-Inclusion-Rate in ChatGPT, Perplexity und Gemini und bauen das wiederholbare Experimentier-Framework auf, das mit LLM-Updates Schritt hält.




.webp)










.webp)



















































.webp)