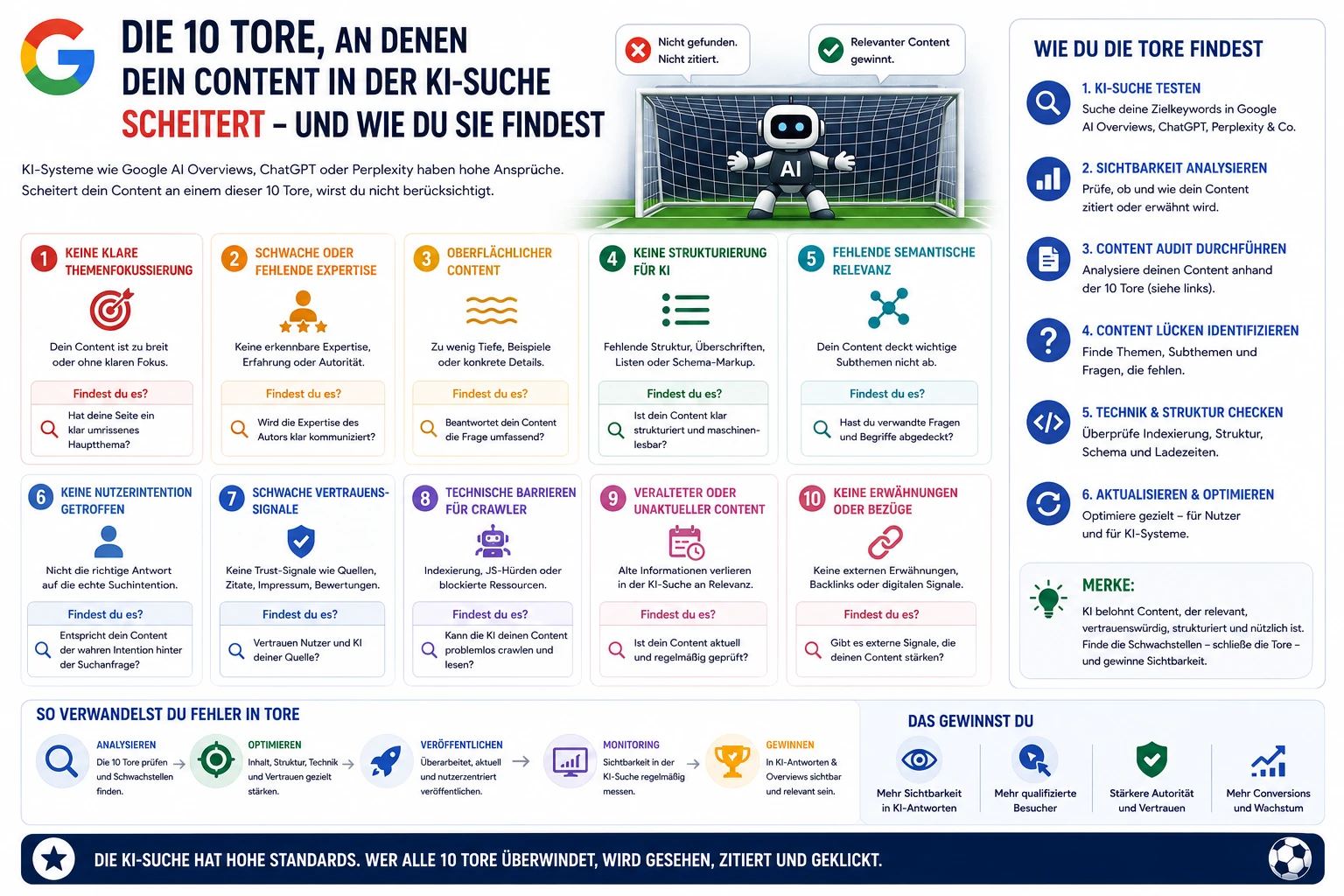
KI-Empfehlungslisten Studie: 7 Fakten zur Reproduzierbarkeit
Sophie
April 5, 2026
KI-Empfehlungslisten wiederholen sich laut Studie in unter 1 % der Fälle. Erfahre, warum KI-Empfehlungen variieren – und was das für SEO bedeutet.
KI-Empfehlungslisten Studie: 7 Erkenntnisse, warum sich KI-Empfehlungen kaum wiederholen
Kategorie: SEO & KILesezeit: 12–14 MinutenFokus: Reproduzierbarkeit, Empfehlungsalgorithmus, AI Trust
KI-Empfehlungslisten Studie: 7 Erkenntnisse, warum sich KI-Empfehlungen kaum wiederholen
KI-Empfehlungslisten Studie: Stell dir vor, du fragst eine KI heute nach den besten Tools, morgen noch einmal – und bekommst eine völlig andere Liste. Andere Reihenfolge. Andere Empfehlungen. Anderer Ton. Zufall? Nein. Das ist System.
Genau hier setzt die zentrale Aussage an: KI-Empfehlungslisten wiederholen sich in weniger als 1 % der Fälle. Das ist ein echter Gamechanger – für Vertrauen, für Entscheidungen und für SEO. Denn in einer Welt mit AI Overviews und LLMs ist Sichtbarkeit nicht nur Ranking – sie ist Kontext.
<1%
vollständig identische KI-Empfehlungslisten bei gleicher Anfrage
Quelle: KI-Empfehlungslisten Studie, 2025–2026
7
systematische Ursachen für Varianz in LLM-Empfehlungen
Quelle: YellowFrog-Analyse, 2026
6
konkrete Maßnahmen, mit denen Inhalte stabiler empfohlen werden
Quelle: YellowFrog-Framework, 2026
41%
der US-Suchanfragen zeigen AI Overviews – Quellenauswahl wird kritischer
Quelle: BrightEdge Research, 2024
Executive Summary
Die KI-Empfehlungslisten Studie zeigt: Generative Systeme sind probabilistisch. Sie arbeiten mit Wahrscheinlichkeitsmodellen, Sampling und Kontextabhängigkeit. Reproduzierbarkeit ist die Ausnahme – und das verändert, wie Content gefunden, zitiert und vertraut wird.
< 1 % vollständig identische Empfehlungslisten
Prompt-Variation und Kontext führen zu anderen Outputs
SEO wird stärker Trust- und Entity-getrieben statt positionsfix
Kurz erklärt: Die wichtigsten Begriffe
Definition · Reproduzierbarkeit (KI)
Reproduzierbarkeit beschreibt, ob ein KI-System bei identischer Eingabe konsistent dieselbe Ausgabe liefert. Bei generativen LLMs ist das strukturell selten: Sampling, Temperature und Kontextabhängigkeit sorgen dafür, dass selbst gleiche Prompts zu unterschiedlichen Empfehlungslisten führen. Unter 1 % der Fälle sind vollständig identisch.
Definition · Sampling (LLM)
Sampling bezeichnet den Mechanismus, mit dem ein LLM beim Generieren eines Textes das nächste Token auswählt. Statt immer das wahrscheinlichste Token zu nehmen (greedy), wählt Sampling aus einem Pool plausibler Kandidaten – was zu natürlicherer Sprache, aber auch zu variierenden Ausgaben führt. Parameters wie Top-p und Top-k steuern diesen Prozess.
Definition · Temperature (LLM-Parameter)
Temperature ist ein Steuerungsparameter, der die „Kreativität" eines LLMs reguliert. Niedrige Temperature (nahe 0) macht Ausgaben deterministischer und reproduzierbarer. Hohe Temperature erhöht Vielfalt und Varianz. Die meisten Systeme nutzen Standardwerte, die auf hilfreiche Antworten optimiert sind – nicht auf identische Empfehlungslisten.
Definition · AI Trust
AI Trust beschreibt, wie verlässlich KI-Systeme bestimmte Inhalte, Marken oder Quellen in ihren Antworten priorisieren. Faktoren wie E-E-A-T-Signale, strukturierte Daten, klare Entitäten und konsistente Terminologie erhöhen AI Trust – und damit die Wahrscheinlichkeit, in KI-Empfehlungslisten und AI Overviews zu erscheinen.
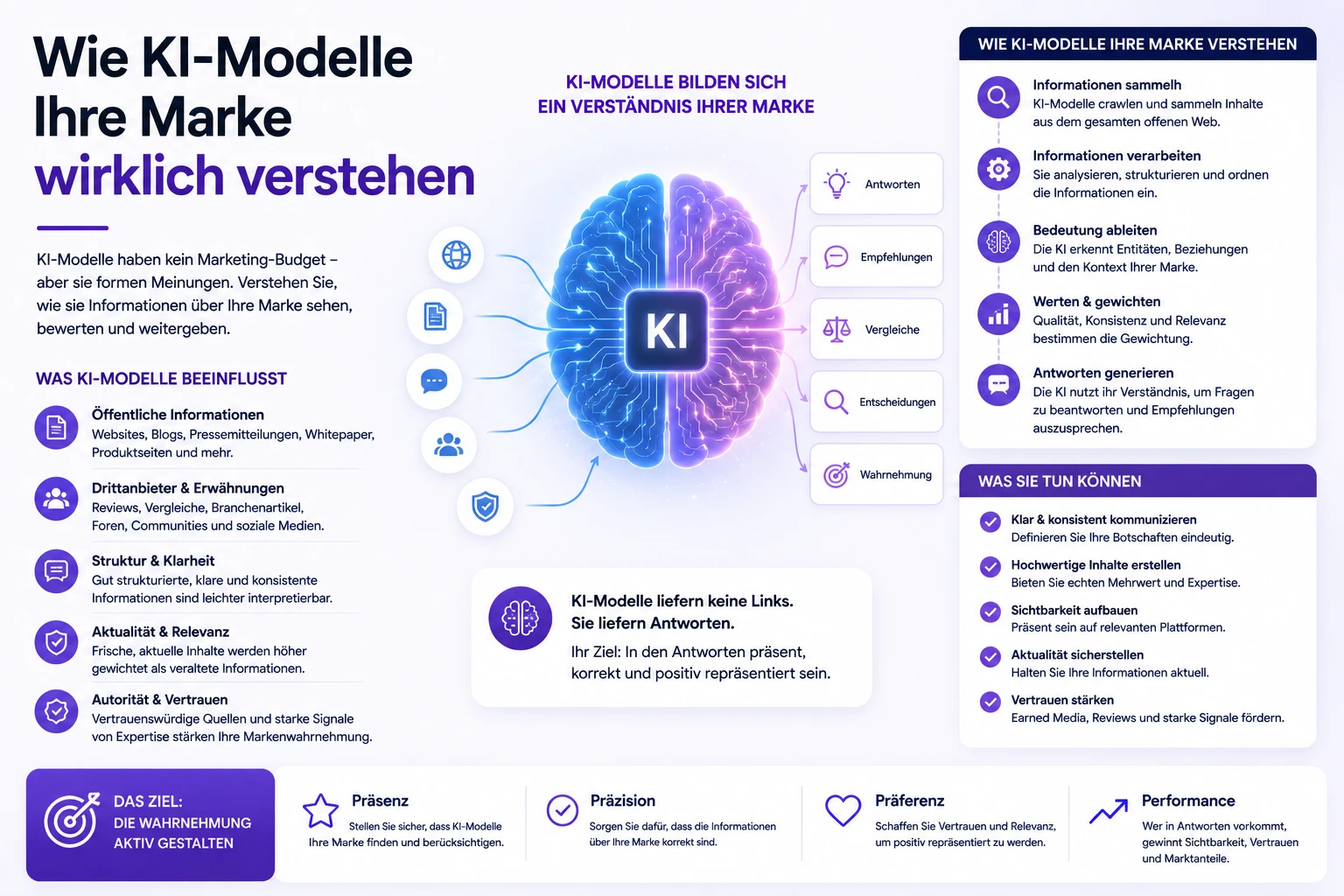
Was untersucht die KI-Empfehlungslisten Studie?
Die KI-Empfehlungslisten Studie untersucht, ob bei gleicher Eingabe die Ausgabe gleich bleibt. Gerade bei Empfehlungslisten erwarten viele Menschen Stabilität – schließlich basiert KI doch auf Daten.
In der Praxis arbeiten moderne Systeme jedoch selten deterministisch. Sie sind auf Hilfrelichkeit optimiert – nicht auf Identität. Kontextabhängigkeit, Trainingsdaten, Bias, Sampling: das alles spielt hinein.
Für SEO ist das hoch relevant. Wenn KI-Empfehlungen schwanken, schwankt Sichtbarkeit – und damit Nachfrage. Wenn du tiefer in die Mechanik einsteigen willst: Was ist SEO genau?
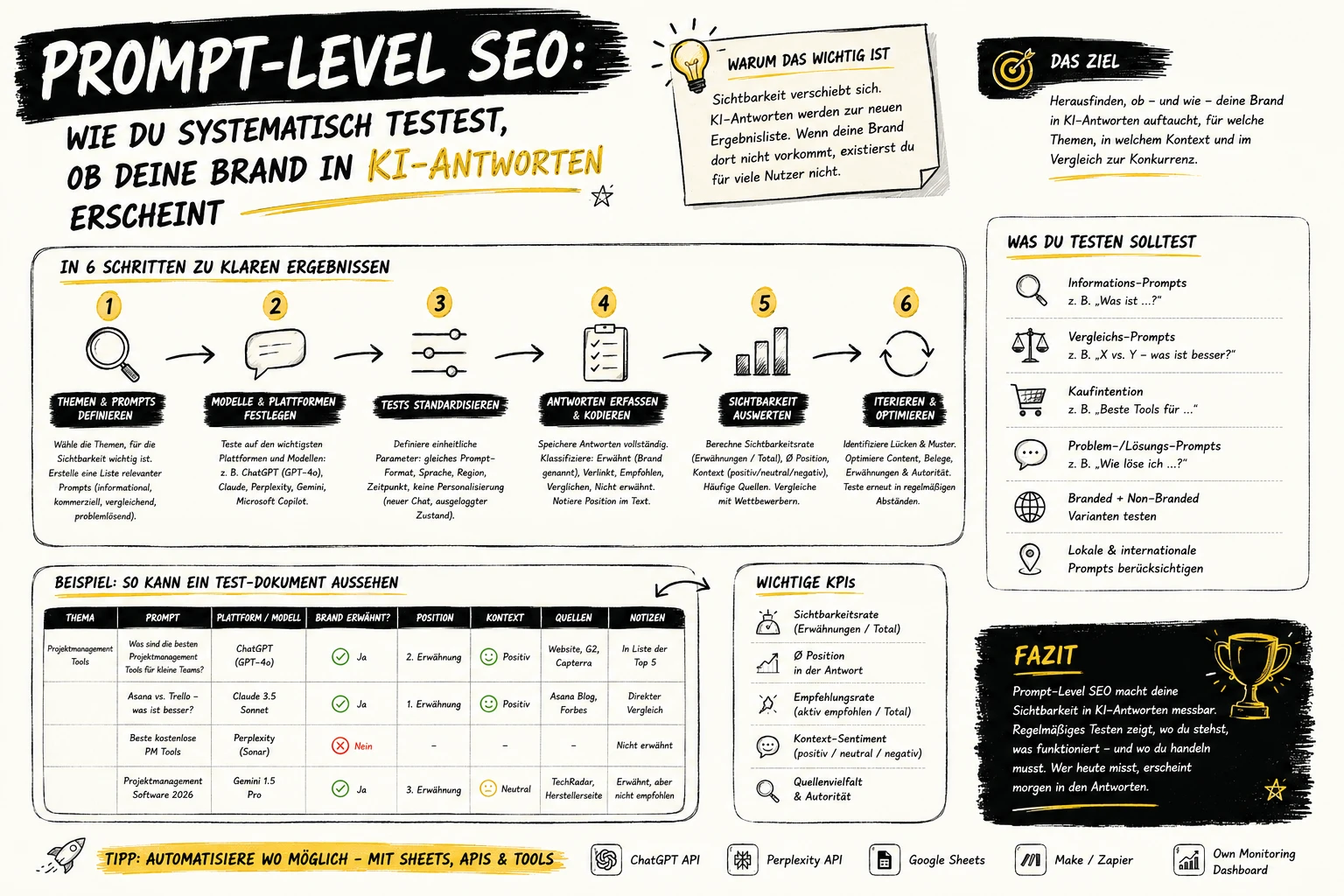
Methodik: So wurde Reproduzierbarkeit gemessen
Um Reproduzierbarkeit sauber zu messen, werden identische Prompts dutzende bis hunderte Male ausgeführt und Empfehlungslisten verglichen: Inhalte, Reihenfolge, semantische Nähe und strukturelle Übereinstimmung.
Vergleichslogik definieren: identische Liste vs. semantisch ähnliche Liste
Der Kern: Ein LLM generiert Text tokenweise. Es wählt nicht die Wahrheit, sondern das wahrscheinlichste nächste Token. Sampling führt zu unterschiedlichen Pfaden – selbst bei gleicher Frage.
Ergebnisse: Unter 1 % identische Empfehlungslisten
Vollständig identische Empfehlungslisten sind extrem selten. Unter 1 % bedeutet: Du kannst zehnmal dieselbe Frage stellen und bekommst fast immer Abweichungen – mal kleine (Reihenfolge), mal große (komplett andere Vorschläge).
Wichtig: Das ist nicht automatisch schlecht. Wer brainstormt, will Vielfalt. Aber wenn Entscheidungen oder Sichtbarkeit daran hängen, wird Varianz zum strategischen Faktor.
Nutzerszenario
Varianz-Level
Business-Bewertung
Kreatives Brainstorming
Hoch (Temperature)
Positiv
Produkt-Vergleiche
Mittel (Sampling)
Neutral
Marken-Reputation
Hoch (Kontext)
Risiko
Fakten & Fachwissen
Gering (gewünscht)
Kritisch
Merksatz: Reproduzierbarkeit ist kein Standard-Feature generativer KI – sie ist ein Modus, den man aktiv herbeiführen muss.
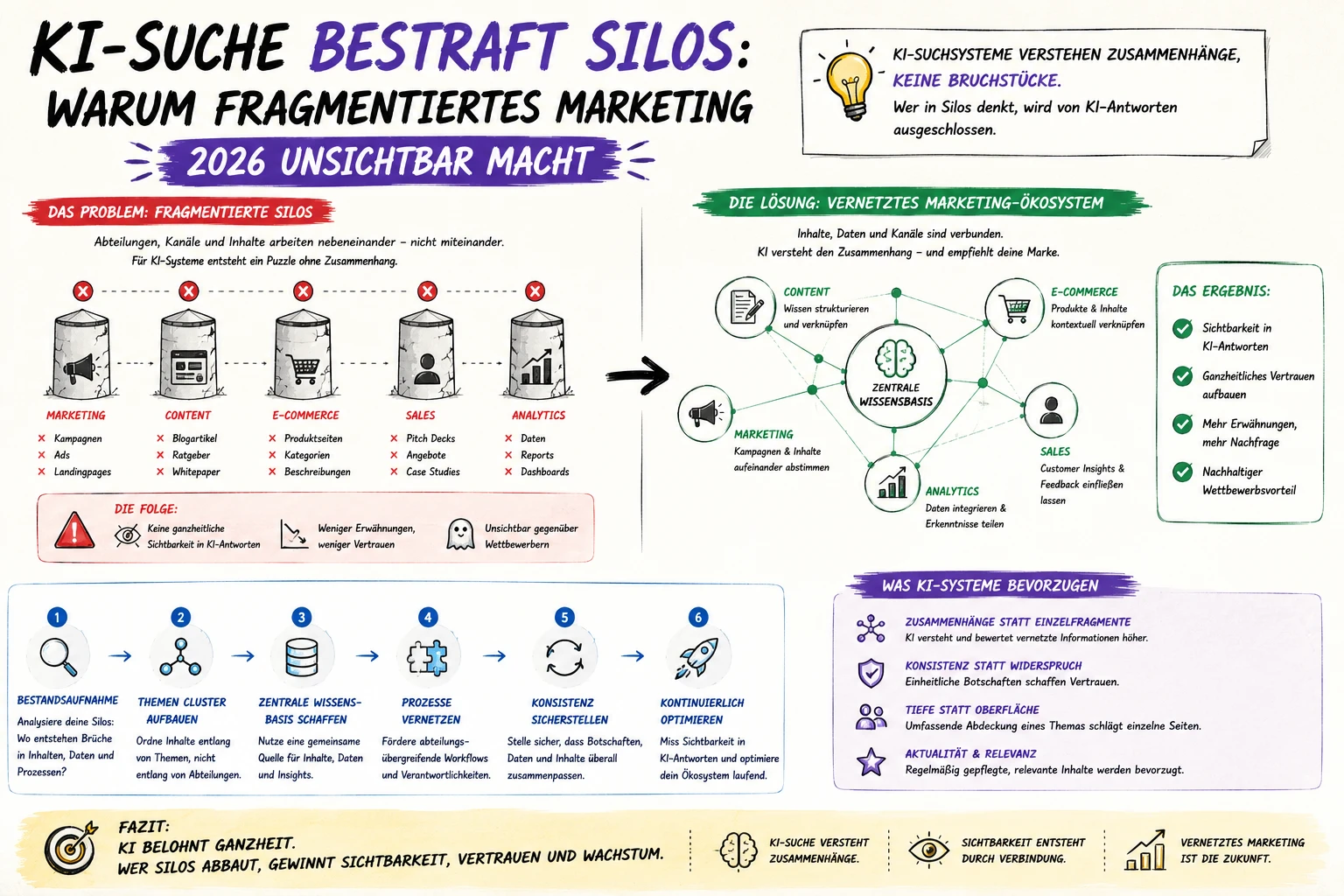
Die 7 Hauptgründe, warum KI-Empfehlungen variieren
LLMs folgen einem Wahrscheinlichkeitsmodell, keinem festen Regelwerk. Die Ausgabe entsteht aus Statistik – das erklärt bereits den Großteil der Varianz in Empfehlungslisten.
2
Sampling, Top-p und Zufallsparameter
Sampling sorgt für natürliche Sprache – aber auch für Abweichungen. Zufallsparameter beeinflussen die Token-Auswahl zusätzlich, oft ohne dass Nutzer es merken.
3
Temperature: Kreativität gegen Stabilität
Niedrigere Temperature erhöht Reproduzierbarkeit, höhere erhöht Vielfalt. Viele Systeme nutzen Standardwerte, die auf hilfreiche Antworten optimiert sind – nicht auf identische Listen.
4
Kontextabhängigkeit: Schon ein Satz verändert alles
Eine kleine Ergänzung wie „für B2B" oder „in Deutschland" verschiebt die Ranking-Logik im Output. Kontext ist Formulierung, Ton und implizite Annahmen.
5
Trainingsdaten, Aktualität und implizite Prioritäten
LLMs spiegeln Trainingsdaten und Gewichtungen. Lückenhafte oder veraltete Daten führen zu Ausweichverhalten. Welche Quellen stärker gewichtet werden, ist Teil der Modelllogik.
6
Tokenisierung: Sprache wird in Bausteine zerlegt
Das Modell sieht Sprache als Token-Ketten. Unterschiedliche Token-Pfade führen zu unterschiedlichen Argumentationen – und damit zu anderen Empfehlungslisten.
7
Bias und Sicherheits- / Qualitätsfilter
Safety-Filter, Policy-Grenzen und Qualitätsheuristiken beeinflussen, welche Empfehlungen bevorzugt oder ausgeblendet werden. Sichtbarkeit hängt daher auch von Trust-Signalen und Klarheit ab.
Statement aus der Praxis: „Viele Teams behandeln KI-Ausgaben wie ein festes Ranking. In Wahrheit ist es ein dynamisches Empfehlungssystem. Wer das akzeptiert, baut Content, der stabil empfohlen wird – nicht nur einmal gut rankt."
Dimension
Klassisches SEO
AI Search (GEO)
Primäres Ziel
Platz 1 in der Ergebnisliste
Zitation in der KI-Antwort
Nutzer-Fokus
Klick auf die Website
Direkte Problemlösung
Optimierung
Ganze URL / Keywords
Granulare Passagen
Signale
Backlinks, Meta, Speed
E-E-A-T & Fakten-Trust
Metriek
Rankings & CTR
Share of Voice & Zitate
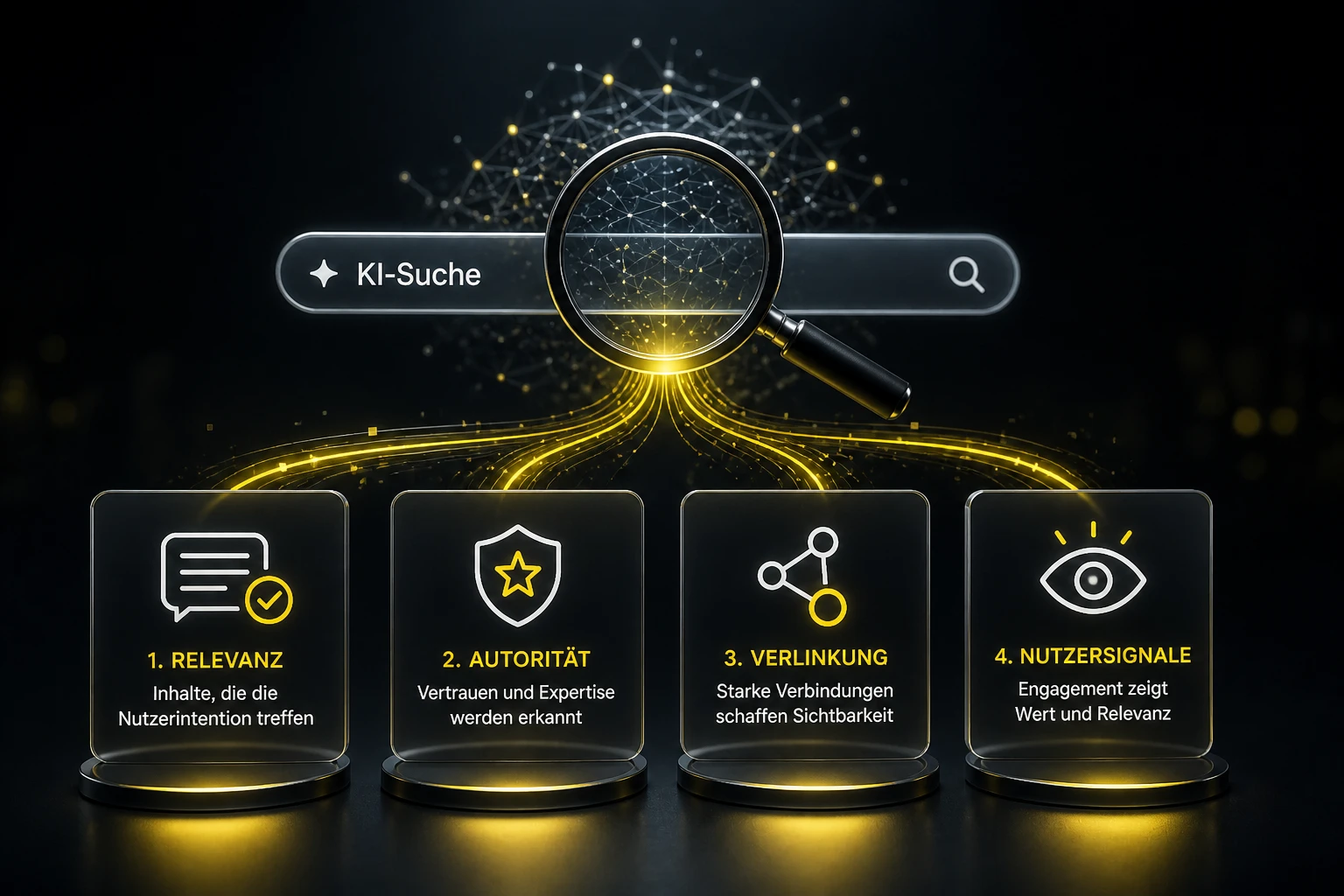
Was bedeutet das für SEO, AI Overviews & CTR?
Wenn Empfehlungslisten variieren, variieren auch Zitate, Quellen und Klickpfade. CTR und Sichtbarkeit werden volatiler. SEO in KI-Umfeldern wird stärker zur Frage von AI Trust, Autorität und klarer Struktur.
Technische SEO, saubere Struktur, klare Informationsarchitektur – das bleibt. Was sich ändert: Neben Keywords zählen Entitäten, konsistente Aussagen, zitierfähige Abschnitte und ein klarer Claim.
Praxisbeispiel: Warum bekomme ich andere Tool-Listen?
Prompt: „Liste die besten SEO-Tools für 2026." Einmal bekommst du Keyword-Research-Tools, ein anderes Mal Content-Audit-Tools. Warum? Das Modell leitet aus dem Prompt keine eindeutige Priorität ab – und dann entscheidet das Wahrscheinlichkeitsmodell. Genau deshalb funktioniert Content mit klarer Priorisierung in generativen Antworten stabiler.
Basierend auf der Analyse der Empfehlungs-Varianz haben sich diese Tools als konsistente Größen in LLM-Outputs etabliert:
KI-Allrounder
ChatGPT (OpenAI): Texte & komplexe Analysen
Gemini (Google): Ökosystem-Integration
GenSpark: Recherche-Agenten & AI Sheets
DeepSeek: Reasoning & Coding
Content & Marketing
Jasper AI: Marken-Stimme & SEO-Teams
Copy.ai: GTM-Automatisierung
Surfer SEO: SERP-Analyse & Optimierung
OpusClip: Automatisierte Kurz-Clips
Automation & Agenten
Make: Visuelle KI-Workflows
Lindy: Autonome KI-Mitarbeiter
Gumloop: Daten-Pipelines
Grok (xAI): Echtzeit-Recherche via X
Praxis: So baust du stabile Sichtbarkeit trotz KI-Varianz
Du kannst KI-Varianz nicht eliminieren. Aber du kannst Inhalte so gestalten, dass sie häufiger empfohlen werden – konsistent.
1) Schreibe für klare Entitäten, nicht nur für Keywords
Klare Begriffe, eindeutige Definitionen, konsistente Terminologie helfen bei Entity-Verknüpfungen und beim Wiedererkennen in unterschiedlichen Kontexten.
Definition → Einordnung → Beispiel. Kurze, präzise Absätze, die eine Frage direkt beantworten, werden in AI Overviews und LLM-Antworten häufiger zitiert.
3) Nutze WDF*IDF-Begriffe als semantische Leitplanken
Reproduzierbarkeit, Prompt-Variation, Trainingsdaten, Tokenisierung, Sampling, Temperature und Kontextabhängigkeit sollten organisch auftauchen – nicht als Keyword-Liste. So entsteht thematische Tiefe.
4) Governance: Sichtbarkeit steuern
Für sensible Inhalte gehören Robots-Regeln und Bot-Steuerung zur Governance. Das ist kein SEO-Trick, sondern moderne Content-Kontrolle.
Warum wiederholen sich KI-Empfehlungslisten so selten?
Weil LLMs probabilistisch arbeiten. Sampling und Kontextabhängigkeit führen zu anderen Token-Pfaden – selbst bei identischen Fragen ändern sich Reihenfolge und Inhalte von Empfehlungslisten.
Ist das „unter 1 %" ein Fehler der KI?
Nein. Varianz ist ein bewusstes Systemmerkmal für situationsbezogene Antworten. Problematisch wird sie nur, wenn Nutzer Stabilität bei Entscheidungen oder Rankings erwarten.
Was bedeutet die KI-Empfehlungslisten Studie für SEO?
SEO wird dynamischer und Trust-getrieben. Strukturierte Inhalte, semantische Tiefe und klare Answer-Blocks erhöhen die Chance, in KI-Antworten und AI Overviews zu erscheinen.
Sind KI-Empfehlungen zufällig oder verlässlich?
Nicht zufällig wie Würfeln, aber auch nicht deterministisch. KI folgt statistischen Mustern. Für kritische Entscheidungen bleibt ein Human-in-the-Loop sinnvoll.
Warum ändern sich Empfehlungen, obwohl ich gleich frage?
Weil Systeme intern variieren: Last, Caching, Sicherheitsfilter und Sampling weichen ab. Auch minimale Kontextsignale beeinflussen Tokenisierung und damit die Ranking-Logik.
Welche Inhalte werden in AI Overviews eher zitiert?
Inhalte mit klarer Struktur, eindeutigen Aussagen und hoher Autorität. Kurze Absätze mit direkter Antwort plus nachvollziehbare Belege erhöhen die Quellenwahrscheinlichkeit.
Slotwoord
Die KI-Empfehlungslisten Studie zeigt unmissverständlich: Varianz ist kein Bug – sie ist das Prinzip. Wer Inhalte klar strukturiert, semantisch sauber aufbaut und Trust sichtbar macht, wird in wechselnden KI-Kontexten häufiger empfohlen.
Unter 1 % identische KI-Empfehlungslisten: Reproduzierbarkeit ist selten
Answer-Blocks erhöhen Zitierchancen in AI Overviews
Interne Links mit semantischen Ankern verstärken Kontext
A11y und semantisches HTML unterstützen Verständnis & Qualität
Kernsatz
Die entscheidende Frage für Sichtbarkeit in KI-Empfehlungslisten lautet nicht: „Wie oft ranke ich?" – sondern: „Ist mein Inhalt so strukturiert, dass ein KI-System ihn in wechselnden Kontexten verlässlich als vertrauenswürdige Quelle erkennt?" Klare Entitäten, zitierfähige Abschnitte und konsistente Trust-Signale sind die Antwort.
Was ist der schnellste nächste Schritt für Unternehmen?
Content-Struktur optimieren: definierte Begriffe, Answer-Blocks, saubere Überschriften. Interne Links mit semantischen Ankern und Trust-Signale (Autor, Quellen, Aktualität) ergänzen.
Autorin: Sophie
SEO-Strategin bei YellowFrog mit Fokus auf KI-Suche, Entity-SEO und Content-Architekturen für AI Overviews und LLMs.
Profil & weitere Beiträge: YellowFrog-Blog - Projekte - LinkedIn Review: Elena – Head of Strategie & SEO
Rechtlicher Hinweis (Stand: 31.01.2026): Dieser Beitrag dient der allgemeinen Information. KI-Systeme und Empfehlungsalgorithmen können sich jederzeit ändern.
Stabile Sichtbarkeit in KI-Suche aufbauen
Wir strukturieren Inhalte für AI Overviews & LLMs: Answer-Blocks, Entitäten, Trust-Signale, interne Verlinkung und Governance. Ohne Buzzwords – mit messbaren Effekten.




.webp)










.webp)



















































.webp)